
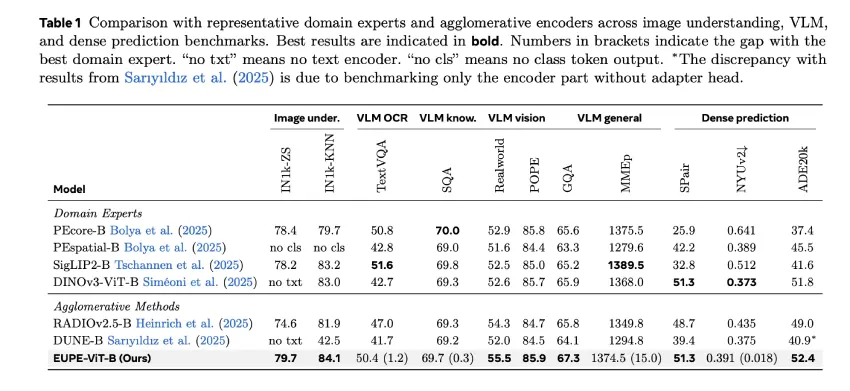
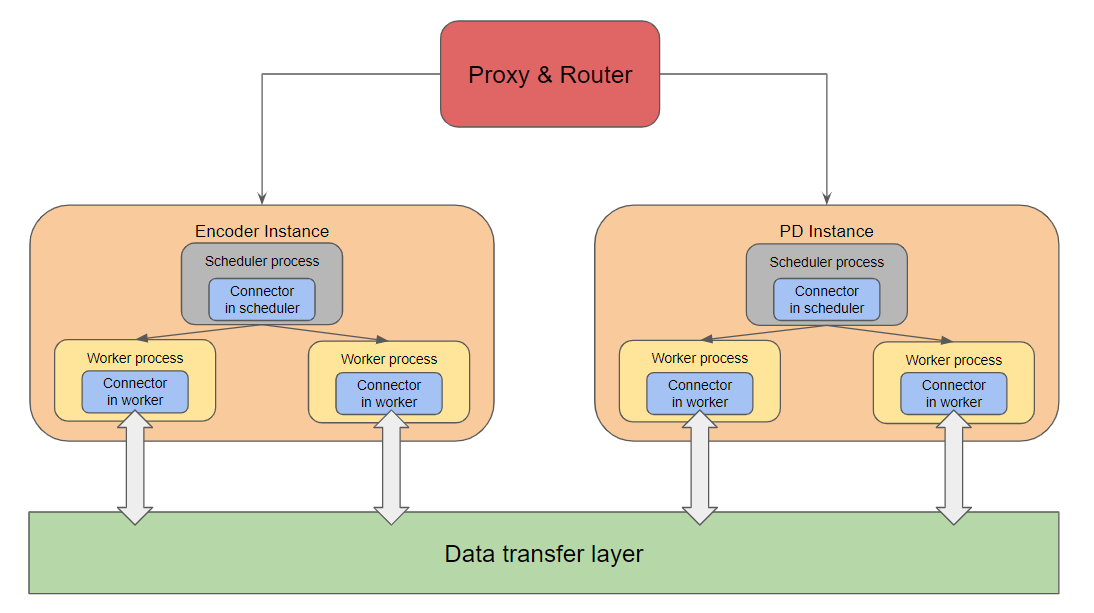
可扩展多模态模型服务的编码器解耦
vLLM Blog
·

Llama.cpp 和 GGUF 中的多模态嵌入
Jina AI
·

对比定位语言-图像预训练
Apple Machine Learning Research
·
FastVLM:视觉语言模型的高效视觉编码
Apple Machine Learning Research
·

大型视觉编码器的多模态自回归预训练
Apple Machine Learning Research
·


