本文介绍了一种视觉自监督学习方法——文本条件JEPA(TC-JEPA),该方法通过图像标题减少特征预测的不确定性。TC-JEPA利用细粒度文本调节器,使图像特征更具语义意义,从而提升下游任务的表现和训练稳定性。该方法在视觉理解和推理任务中优于对比学习,展示了新的基于特征预测的视觉-语言预训练范式。
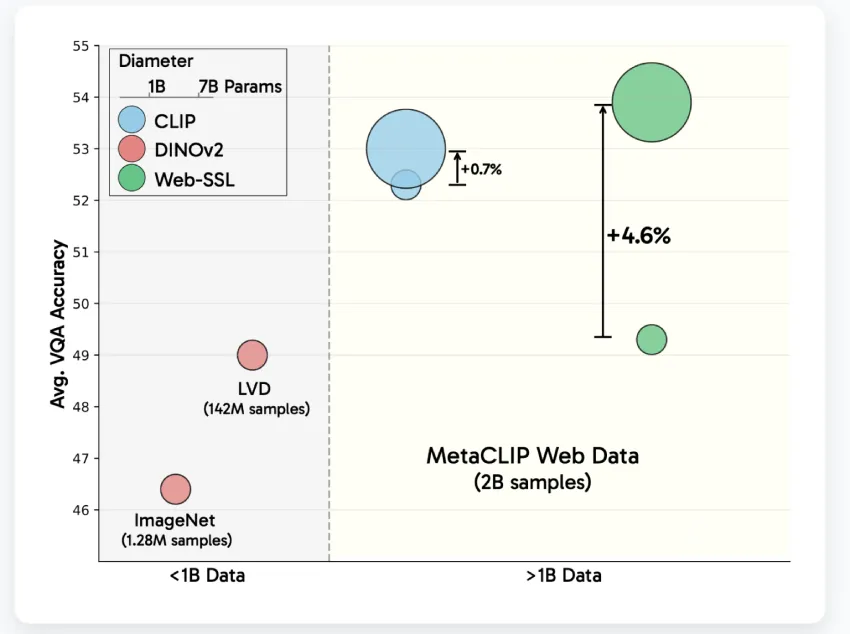
Meta近期发布了WebSSL模型,探索无语言视觉自监督学习的潜力。该模型在大规模图像数据集上训练,展现了在视觉问答和OCR等任务中的竞争力,挑战了语言监督的重要性,并强调了数据集组成和模型规模的影响。WebSSL为未来的多模态系统提供了开源基础。
完成下面两步后,将自动完成登录并继续当前操作。