
Meta AI 发布 Web-SSL:一种可扩展且无需语言的视觉表征学习方法
内容提要
Meta近期发布了WebSSL模型,探索无语言视觉自监督学习的潜力。该模型在大规模图像数据集上训练,展现了在视觉问答和OCR等任务中的竞争力,挑战了语言监督的重要性,并强调了数据集组成和模型规模的影响。WebSSL为未来的多模态系统提供了开源基础。
关键要点
-
Meta发布WebSSL模型,探索无语言视觉自监督学习的潜力。
-
WebSSL模型在大规模图像数据集上训练,展现了在视觉问答和OCR等任务中的竞争力。
-
无语言视觉自监督学习在多模态推理中尚未得到充分利用。
-
WebSSL模型参数范围从3亿到70亿,专门在MetaCLIP数据集的图像子集上进行训练。
-
WebSSL模型的评估使用Cambrian-1进行,涵盖多个视觉理解任务。
-
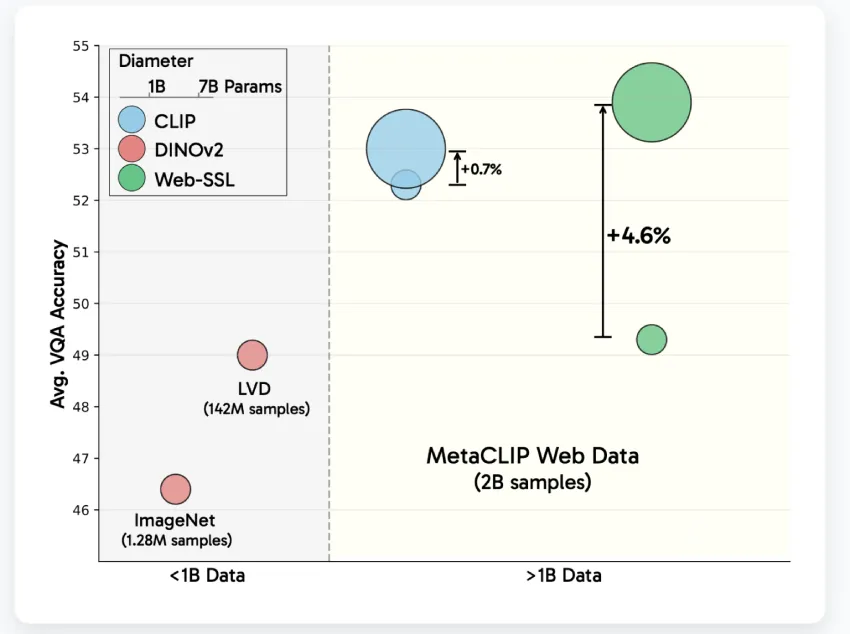
随着模型规模的增加,WebSSL模型的VQA性能呈现出近乎对数线性的提升。
-
数据组成至关重要,过滤训练数据后WebSSL在OCR和图表任务上表现优于CLIP。
-
高分辨率训练进一步缩小了WebSSL与高分辨率模型的性能差距。
-
WebSSL与预训练语言模型的对齐效果随着模型规模和训练次数的增加而提升。
-
WebSSL研究提供了证据,表明视觉自监督学习是语言监督预训练的可行替代方案。
延伸解读
无语言视觉学习的潜力
Meta的WebSSL模型展示了无语言视觉自监督学习的强大潜力,尤其是在视觉问答和OCR任务中。与传统依赖语言监督的模型相比,WebSSL在特定任务上表现出更高的灵活性和可扩展性,表明未来的多模态系统可以在更少的语言依赖下实现更好的性能。
数据组成的重要性
WebSSL的研究强调了训练数据组成对模型性能的关键影响。通过过滤训练数据,仅保留富文本图像,WebSSL在OCR和图表任务上超越了CLIP,显示出数据质量和相关性在视觉学习中的重要性。
模型规模与性能关系
WebSSL模型的性能随着参数数量的增加而显著提升,尤其是在视觉问答任务中。这一发现与CLIP形成对比,后者在超过30亿参数后性能趋于稳定,提示研究者在设计视觉模型时应考虑规模的影响。
高分辨率训练的优势
高分辨率训练对WebSSL模型的性能提升至关重要,尤其是在处理文档密集型任务时。通过提高图像分辨率,WebSSL能够缩小与其他高分辨率模型的性能差距,表明在视觉学习中,训练细节对最终效果有显著影响。
延伸问答
WebSSL模型的主要特点是什么?
WebSSL模型是一种无语言视觉自监督学习方法,参数范围从3亿到70亿,专门在MetaCLIP数据集的图像子集上进行训练。
WebSSL在视觉问答任务中的表现如何?
WebSSL在视觉问答任务中展现出竞争力,随着模型规模的增加,其性能呈现出近乎对数线性的提升。
WebSSL模型如何影响多模态学习的研究?
WebSSL的研究挑战了语言监督在多模态理解中的重要性,提供了视觉自监督学习作为可行替代方案的证据。
WebSSL模型的训练数据组成有什么重要性?
数据组成至关重要,通过过滤训练数据,WebSSL在OCR和图表任务上表现优于CLIP,提升幅度可达13.6%。
WebSSL与CLIP模型的比较结果如何?
WebSSL在所有视觉问答类别中保持竞争力,并在更大规模的视觉任务中表现优于CLIP,尤其是在OCR和图表任务上。
WebSSL模型的高分辨率训练有什么效果?
高分辨率训练使WebSSL模型在文档密集型任务中缩小了与高分辨率模型的性能差距。
