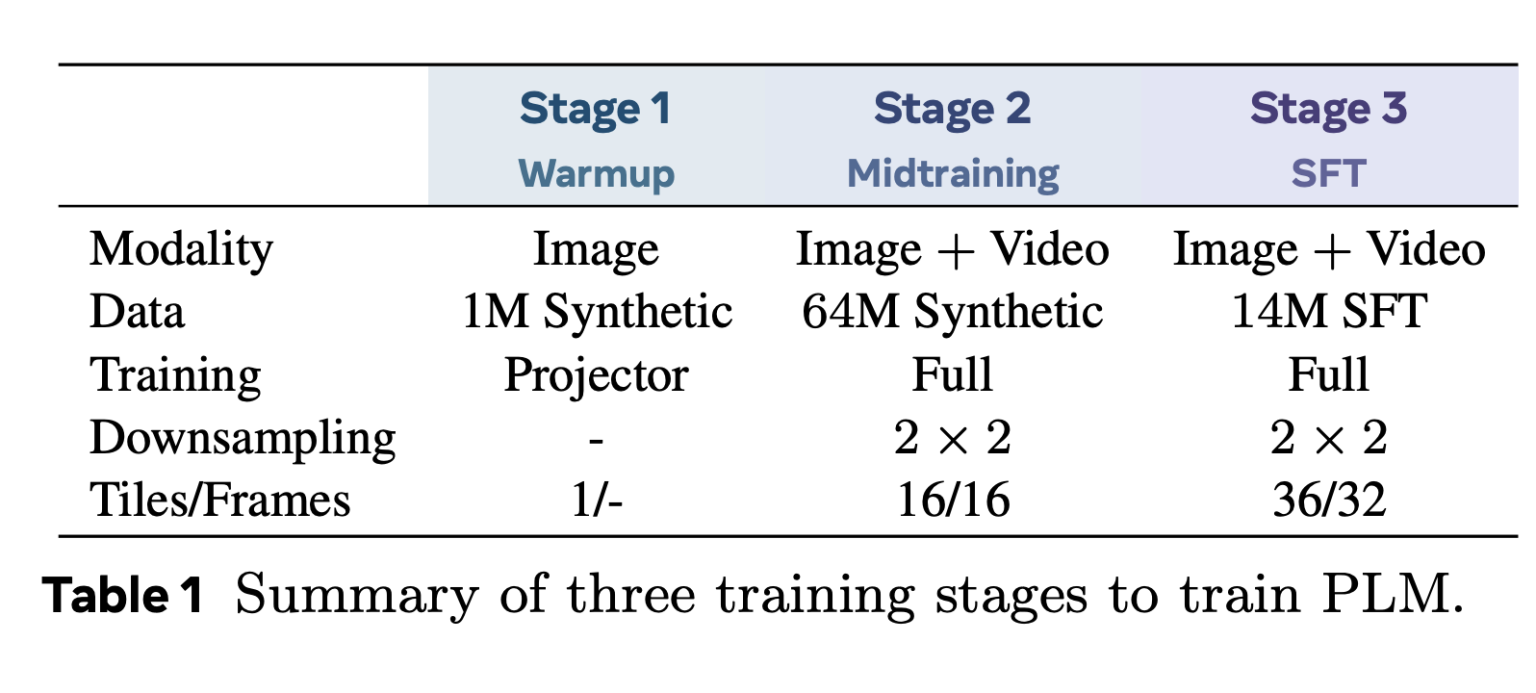
Meta AI推出了感知语言模型(PLM),这是一个开放且可复现的视觉语言建模框架,支持图像和视频输入。PLM通过合成数据和人工标记数据进行训练,强调透明性和可评估性,集成了视觉编码器和不同参数的语言解码器,采用多阶段训练流程。PLM发布了两个高质量视频数据集,支持细粒度视频理解,并在多个基准测试中表现优异,推动了多模态人工智能研究。
完成下面两步后,将自动完成登录并继续当前操作。