《编程面试指南》为软件工程师提供了技术面试的全面参考,包括编码原则、算法、设计模式和常见面试问题。LOMO是一种优化大型语言模型的方法,支持低内存微调。localrf算法用于从视频中重建场景,SAM-PT则提供零-shot视频分割工具。
本研究提出了改进版SAM2模型,旨在提升图像和视频分割模型在跨领域适应性和泛化能力方面的表现。尽管特定领域适应性仍需进一步研究,但其在医疗成像等专业领域的应用潜力巨大。
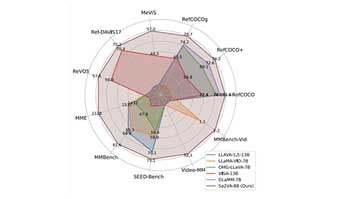
多模态大型语言模型Sa2VA结合视频分割与语言处理,提升图像和视频理解效率。该模型采用创新的解耦设计和特殊标记机制,支持多任务,表现优于以往系统,标志着多模态AI的重大进步。
本研究提出了一种改进的无训练视频对象分割方法SAM2Long,解决了Segment Anything Model 2在复杂长视频分割中的误差累积问题,通过考虑每帧的分割不确定性,增强了分割和跟踪能力。
这篇论文探讨了Segment Anything Model(SAM)在图像分割中的应用及未来发展。SAM是首个通用基础模型,能够进行零-shot图像分割,但在医学图像分割方面仍面临挑战。研究表明,结合手动标注和领域知识可以提升模型性能。此外,论文还介绍了SAM2在视频分割中的应用,展示了其在不同场景下的表现差异及改进建议。
该文介绍了Meta AI Research开发的Segment Anything Model(SAM)及其后续版本SAM 2。研究表明,SAM在图像和视频分割中表现优异,尤其在手术视频和高分辨率图像处理方面。SAM 2通过新的评估方法和用户交互数据引擎显著提高了分割准确性和效率,展示了其在计算机视觉领域的重要性和广泛应用潜力。
Meta开源了SAM 2模型,可以根据视频帧上的提示(点击、框选或遮罩)准确识别和分割图像或视频中的任何对象。SAM 2模型已应用于医学图像分割等多个领域。Meta还发布了用于训练SAM 2的SA-V数据集,可在HyperAI网站上下载。SA-V数据集是一个大型多样化的视频分割数据集,为未来的计算机视觉工作提供了丰富的数据资源。
Segment Anything (SAM)是一个用于图像分割的基础模型,具备任务迁移和零样本学习能力。虽然SAM在自然图像分割任务中表现优异,但在医学图像分割方面仍需手动标注以提高准确性。最新的SAM 2模型在视频分割中显著提升了准确性,但在特定应用上仍存在局限性。
本文探讨了Segment Anything Model(SAM)及其改进版本SAM2在图像和视频分割中的应用。研究发现,SAM在高分辨率图像处理上表现良好,但在某些情况下性能下降。为此,提出了个性化方法PerSAM,结合目标引导注意力等技术以提升分割效果。呼吁对SAM进行进一步探索,以推动其在医学图像等领域的发展。
Meta推出了下一代图像和视频分割模型SAM 2,支持实时对象分割,性能优于前代。该模型能够处理未见对象,适用于视频效果和数据标注等多种应用。开源代码和SA-V数据集将共享,包含51,000个视频和600,000个掩码,推理速度接近实时,推动计算机视觉的发展。
本文提出了一种完全无监督的视频多目标分割方法,通过空间绑定和高级语义特征重建中间帧,成功在YouTube视频中分割复杂对象。该方法结合目标检测、外观分割和时间追踪,显著提升了分割效率和准确性,并在多个数据集上超越了现有技术。
本文介绍了SAMFlow模型,该模型将Segment Anything Model(SAM)的图像编码器嵌入FlowFormer,旨在解决光流估计中的片段化问题,并在多个数据集上表现优异。此外,研究还探讨了基于运动线索的分割方法和无监督视频对象分割,显示出在视频分割任务中的显著优势。
本文介绍了一种基于神经网络的视频分割方法,能够有效区分视频中的独立运动物体。研究利用多种信息源进行模型训练,并在多个数据集上取得良好表现。提出的自监督学习和语言引导的分割方法提升了视频表示质量和分割准确性。此外,开发了名为MeViS的大规模数据集,以支持运动表达引导的视频分割研究。
通过外观优化和时间一致性,提出了一种独立发现、分割和跟踪复杂视觉场景中独立移动物体的方法。该方法在多个视频分割基准上表现出竞争力,并在多物体分割问题上优于现有模型。研究发现该模型可用作逐帧Segment Anything模型的提示。
该论文综述了视频分割中使用的深度学习算法,包括对象分割和语义分割,并提供了这两种方法和数据集的详细概述,以及在几个数据集上的性能评估和未来研究机会。
完成下面两步后,将自动完成登录并继续当前操作。

![介绍 SAM 2:下一代 Meta 视频和图像分割模型 [译]](https://scontent-ord5-1.xx.fbcdn.net/v/t39.2365-6/452258162_1278169679835253_6611651848984223695_n.png?_nc_cat=101&ccb=1-7&_nc_sid=e280be&_nc_ohc=Gwx36k7z7sUQ7kNvgHKfDLX&_nc_ht=scontent-ord5-1.xx&oh=00_AYAO2clEdTyi8UF1zXRROBNyK1VKYJj0a2hBm0HlptK_yA&oe=66C295BA)
