
Sa2VA:通过 SAM-2 和 LLaVA 集成实现密集基础视频和图像理解的统一 AI 框架
内容提要
多模态大型语言模型Sa2VA结合视频分割与语言处理,提升图像和视频理解效率。该模型采用创新的解耦设计和特殊标记机制,支持多任务,表现优于以往系统,标志着多模态AI的重大进步。
关键要点
-
多模态大型语言模型Sa2VA结合视频分割与语言处理,提升图像和视频理解效率。
-
Sa2VA采用创新的解耦设计和特殊标记机制,支持多任务。
-
该模型在细粒度视频内容理解方面表现优于以往系统。
-
Sa2VA通过最少的一次性指令调整克服现有多模态大型语言模型的局限性。
-
模型集成了SAM-2与LLaVA,统一文本、图像和视频到共享的LLM标记空间中。
-
推出的Ref-SAV数据集包含复杂视频场景中的72K多个对象表达,确保强大的基准测试能力。
-
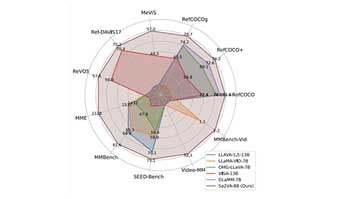
Sa2VA在指涉分割任务上取得最佳结果,优于之前的系统。
-
在对话能力和视频基准测试中,Sa2VA表现出色,显示出其效率和有效性。
-
Sa2VA代表了多模态理解的重大进步,解决了感知与语言理解结合的长期挑战。
延伸解读
多模态AI的进步
Sa2VA模型的推出标志着多模态AI领域的一次重大进步。通过将视频分割与语言处理相结合,Sa2VA不仅提升了图像和视频的理解效率,还解决了以往模型在开放式语言理解和对话能力上的不足。这种创新的解耦设计使得模型在处理复杂任务时更加灵活和高效。
Ref-SAV数据集的价值
Ref-SAV数据集的推出为Sa2VA模型提供了强大的基准测试能力。该数据集包含72K多个对象表达,确保了模型在复杂视频场景中的表现。这一数据集的丰富性和多样性将有助于推动未来多模态理解研究的发展,提供更为全面的评估标准。
模型的实用性与局限性
尽管Sa2VA在多个基准测试中表现出色,但其实际应用仍需关注模型的计算效率和适用范围。虽然该模型在指涉分割和对话任务上取得了优异成绩,但在特定场景下的表现可能仍受限于训练数据的多样性和质量。因此,用户在应用时应考虑这些因素。
延伸问答
Sa2VA模型的主要功能是什么?
Sa2VA模型结合视频分割与语言处理,提升图像和视频理解效率。
Sa2VA是如何克服现有多模态大型语言模型的局限性的?
Sa2VA通过最少的一次性指令调整,支持广泛的图像和视频任务,从而克服了现有模型的局限性。
Sa2VA的创新设计有哪些特点?
Sa2VA采用创新的解耦设计和特殊标记机制,支持多任务处理。
Ref-SAV数据集的作用是什么?
Ref-SAV数据集包含复杂视频场景中的72K多个对象表达,确保强大的基准测试能力。
Sa2VA在视频基准测试中的表现如何?
Sa2VA在MeVIS、RefDAVIS17和ReVOS等视频基准测试中表现出色,远超之前的系统。
Sa2VA如何实现文本、图像和视频的统一处理?
Sa2VA通过将SAM-2与LLaVA集成,统一文本、图像和视频到共享的LLM标记空间中。
