

直播连麦的技术原理
实时互动网
·
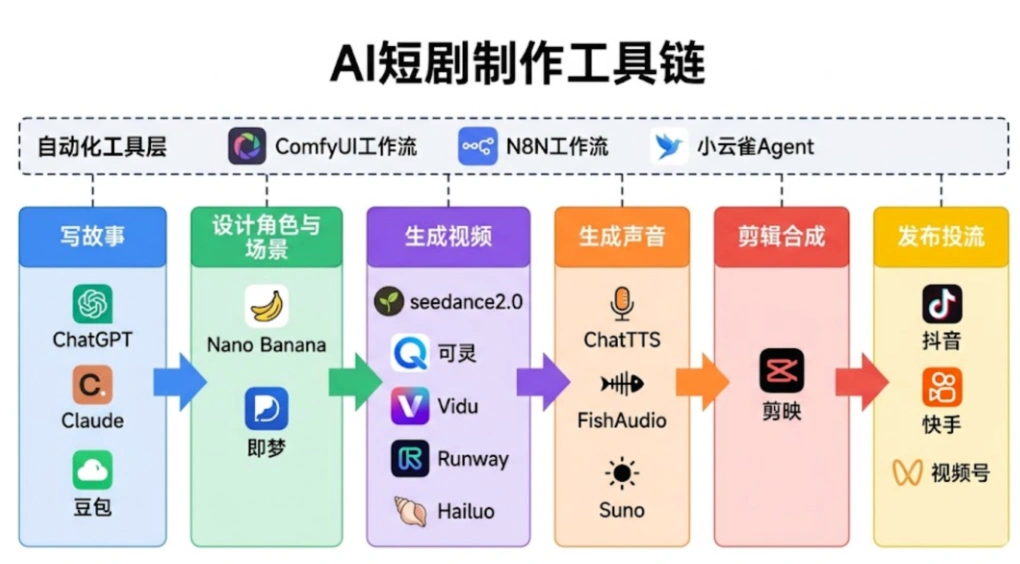
第5章:工具篇——使用小云雀Agent生成短剧
王欣的博客
·



探索 GPUImage 音视频技术(17):高级视频技术
实时互动网
·
/cdn.vox-cdn.com/uploads/chorus_asset/file/25495967/Blink_Moments_BackYard.jpg)
Blink,精彩时刻一网打尽
The Verge
·
