

Supermicro推出一系列搭载Arm AGI CPU的AI解决方案
全球TMT-美通国际
·

Trainium3 UltraServers正式可用,由亚马逊云科技首款3nm AI芯片驱动
全球TMT-美通国际
·

元脑SD200超节点AI服务器助力DeepSeek R1创造国内大模型最快token生成速度
全球TMT-美通国际
·


使用Rust加速Python:实用指南
DEV Community
·


并行处理的GPU计算创新替代方案
DEV Community
·

适用于大型内存数据库的 Amazon EC2 大内存 U7i 实例
亚马逊AWS官方博客
·
AWS Graviton3 加速 Flink 作业执行:Benchmark
亚马逊AWS官方博客
·
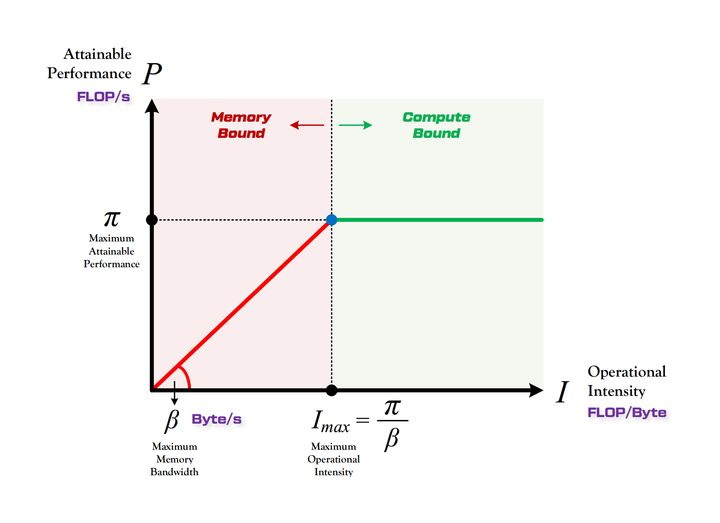
roofline model
plus studio
·
新产品 — 第七代内存优化型 Amazon EC2 实例(R7i)
亚马逊AWS官方博客
·

TensorRT中的int8量化
李文举
·
