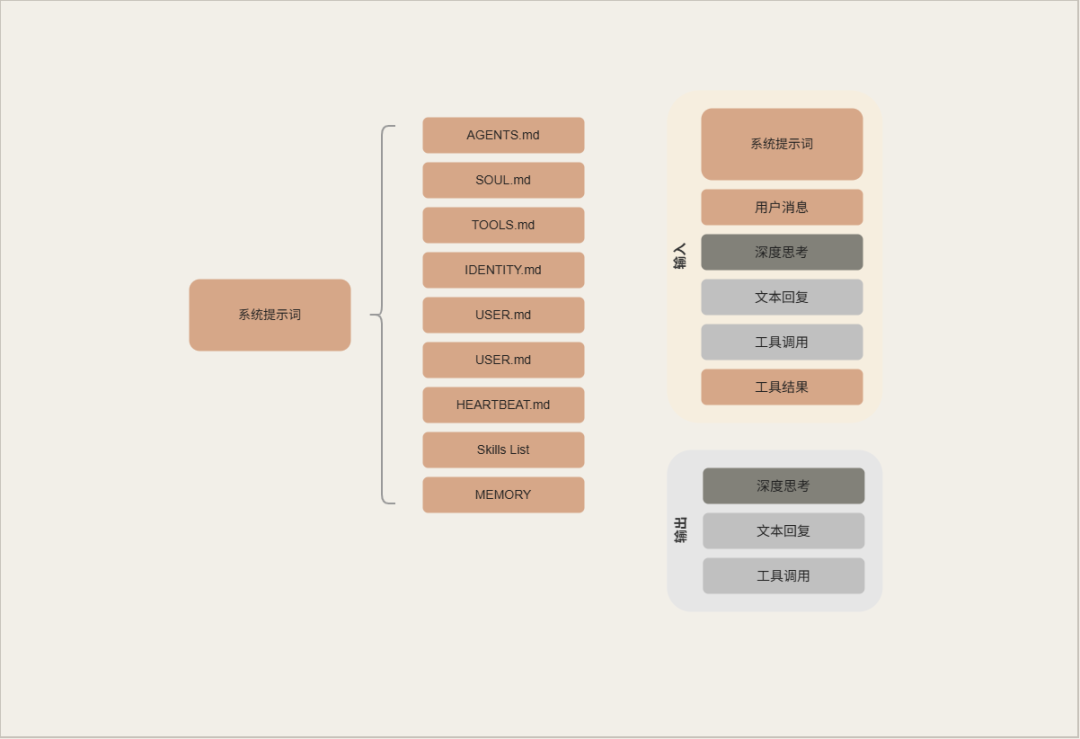
随着AI智能体如OpenClaw的普及,工具增多使得AI容易“失忆”。上下文窗口限制了AI的记忆容量,导致重要信息被压缩或删除。理解这一点有助于更有效地使用AI,避免信息丢失。
该研究提出了一种基于混合记忆架构(MoM)的线性序列建模方法,解决了记忆状态压缩导致的回忆性能不足问题。通过多个独立记忆状态和路由网络,显著提升了记忆容量,减少了干扰。实验结果表明,MoM在回忆密集型任务中表现优异,超越了现有技术,接近Transformer模型的性能。
本文研究了关联记忆模型与深度学习神经网络的关系,提出了多种提高记忆容量和检索效率的模型和技术。研究表明,不同的相似度测量方法能增强模型性能,并探讨了顺序学习在神经网络中的挑战及解决方案。新模型CDAM通过整合自关联和异关联,展示了在处理现实数据和执行任务中的有效性。
研究表明,变压器在记忆容量方面效率高,在下一令牌预测中可用$ ilde{O}(\sqrt{N})$参数有效记忆标签,输入长度影响小。在序列到序列设置中,$ ilde{O}(\sqrt{nN})$参数是充分且必要的,揭示了自注意力机制与前馈网络间的瓶颈。研究还分析了变压器组件对表达能力的影响,并提出基于Hopfield网络的理论框架解释注意力机制。
本研究填补了大型语言模型(LLMs)在记忆能力方面的理论空白,通过比较不同模型的记忆容量来验证LLMs的性能。研究揭示了LLMs与人脑在工作机制上的异同。
完成下面两步后,将自动完成登录并继续当前操作。