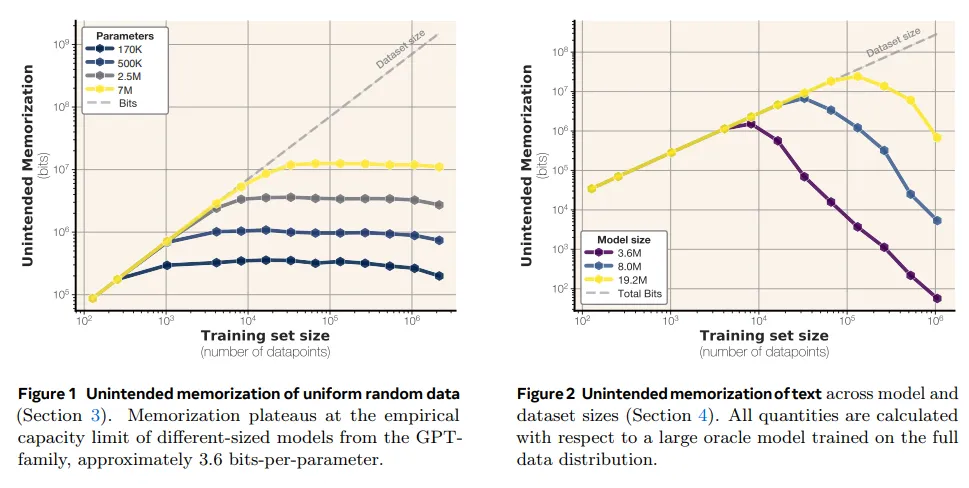
研究者质疑现代语言模型的记忆行为,提出新方法评估模型对数据点的理解,区分非预期记忆与泛化。实验表明,GPT系列模型的记忆容量约为3.6位/参数,且随着训练集增大,记忆力下降。该研究为理解模型行为提供了框架,推动未来模型评估与隐私研究。
本文研究了扩散概率生成模型的泛化能力,发现确定性采样器生成的数据与训练集高度相关,导致泛化能力差。通过实验验证了训练模型的微小区别对性能的影响,并提出了新的训练目标以改善泛化能力。此外,研究探讨了模型的记忆行为及其对生成质量的影响,提出了有效的加权策略以解决估计偏差问题,展示了扩散模型在高维数据学习中的优势。
本研究探讨了扩散模型的记忆行为及其影响因素,发现数据分布、模型配置和训练过程显著影响模型输出。提出了一种高效的数据归因方法,以提高扩散模型的可解释性和可控性。研究表明,合成数据在分类性能上不如真实数据,扩散模型在复制训练数据分布方面仍需改进。
这篇文章探讨了大型语言模型(LLMs)的记忆行为及其对隐私的影响。研究发现,模型在训练过程中可能记忆个人可识别信息(PII),并在推理中泄露。为减轻隐私风险,建议采用记忆减轻技术,并强调在模型训练中需谨慎处理数据以保护隐私。
本研究探讨了扩散模型的记忆行为,发现数据分布、模型配置和训练过程对记忆有显著影响。提出了一种新的dropout方法以减少记忆化的准确性,降低泛化差距。同时,研究提出了DEPN框架,用于检测和编辑隐私神经元,显著降低数据泄漏风险。
完成下面两步后,将自动完成登录并继续当前操作。