
语言模型到底能记忆多少内容?Meta 的新框架定义了比特级的模型容量
内容提要
研究者质疑现代语言模型的记忆行为,提出新方法评估模型对数据点的理解,区分非预期记忆与泛化。实验表明,GPT系列模型的记忆容量约为3.6位/参数,且随着训练集增大,记忆力下降。该研究为理解模型行为提供了框架,推动未来模型评估与隐私研究。
关键要点
-
研究者质疑现代语言模型的记忆行为,提出新方法评估模型对数据点的理解。
-
现有方法无法有效区分非预期记忆与泛化,存在局限性。
-
新方法将记忆分为非预期记忆和泛化,计算总记忆以准确估计模型容量。
-
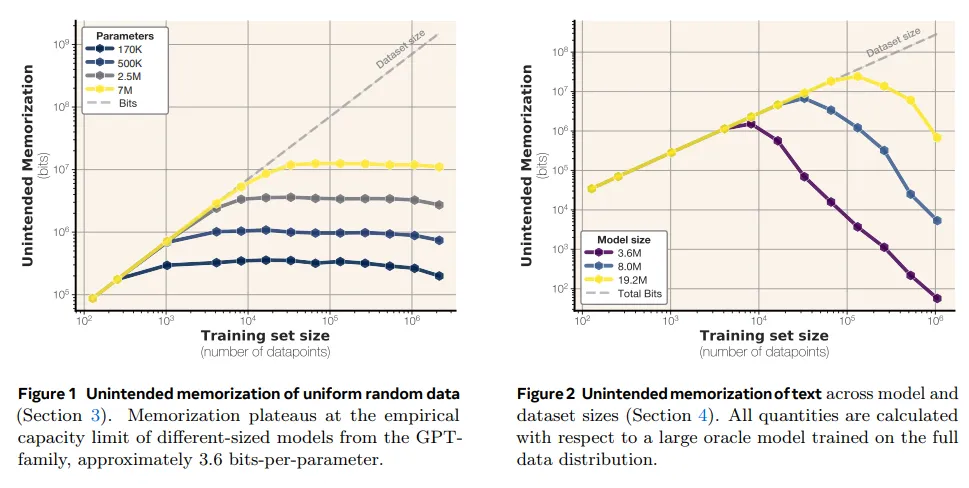
实验表明,GPT系列模型的记忆容量约为3.6位/参数,随着训练集增大,记忆力下降。
-
研究团队使用GPT-2架构训练了数百个模型,探索模型容量与数据大小的关系。
-
随着训练数据集大小接近模型容量,测试损失会经历初期减少后再次改善的双重下降现象。
-
准确估计模型记忆需要重复数据删除并参考Oracle模型来确定基线压缩率。
-
成员推断的成功率随着数据集的增长变得不可靠,尤其是对于大参数模型。
-
该研究为理解模型行为提供了框架,推动未来模型评估与隐私研究。
延伸解读
模型记忆与泛化的区别
研究者提出的新方法有效区分了语言模型的非预期记忆与泛化。这一划分有助于更准确地评估模型的真实能力,尤其是在处理复杂数据时。理解这两者的差异对于改进模型设计和训练策略至关重要。
记忆容量的影响因素
实验结果显示,GPT系列模型的记忆容量约为3.6位/参数,且随着训练集的增大,模型的记忆力反而下降。这提示研究者在选择训练数据时需谨慎,以避免过度拟合和记忆能力的损失。
成员推断的可靠性问题
随着数据集规模的扩大,成员推断的成功率显著下降,尤其是在大参数模型中。这一现象表明,模型在处理大规模数据时可能面临隐私风险,未来的研究需关注如何提高推断的可靠性。
延伸问答
现代语言模型的记忆行为存在哪些质疑?
研究者质疑现代语言模型是否能够以有意义的方式记忆训练数据,尤其是常用技术无法有效区分记忆与泛化。
Meta提出的新方法如何评估语言模型的记忆容量?
新方法将记忆分为非预期记忆和泛化,通过去除泛化来准确估计模型容量,结果显示GPT系列模型的容量约为3.6位/参数。
随着训练集增大,语言模型的记忆力会发生什么变化?
随着训练集规模的增加,模型的记忆力会下降,尤其是在数据集接近模型容量时。
研究团队使用了什么架构来训练模型?
研究团队使用了GPT-2架构,训练了数百个模型,参数数量从10万到2000万不等。
什么是双重下降现象?
双重下降现象是指随着训练数据集大小接近模型容量,测试损失最初减少后,再次改善的现象。
这项研究对未来模型评估有什么影响?
该研究为理解模型行为提供了框架,推动未来在模型评估、隐私和可解释性方面的发展。
