

一分钟读论文:《选择性形式化与门控执行》
Micropaper
·




一分钟读论文:《通过自我调节模拟规划实现高效智能体推理》
Micropaper
·


一分钟读论文:《TOKI:LLM Agent持久记忆矛盾解决的双时间算子代数》
Micropaper
·

一分钟读论文:《用 LLM 作为开发者评估 Agent 开发框架》
Micropaper
·

一分钟读论文:《思想的经济:Agent经济交互中的多智能体智能涌现》
Micropaper
·

人工智能论文评审:通过人类反馈训练语言模型以遵循指令(InstructGPT)
freeCodeCamp.org
·

一分钟读论文:《元认知记忆策略优化》
Micropaper
·

一分钟读论文:《SpecBench:面向软件工程 Agent 的规范级推理评估》
Micropaper
·

一分钟读论文:《像团队一样进化:基于大语言模型的多智能体系统协作自我进化》
Micropaper
·
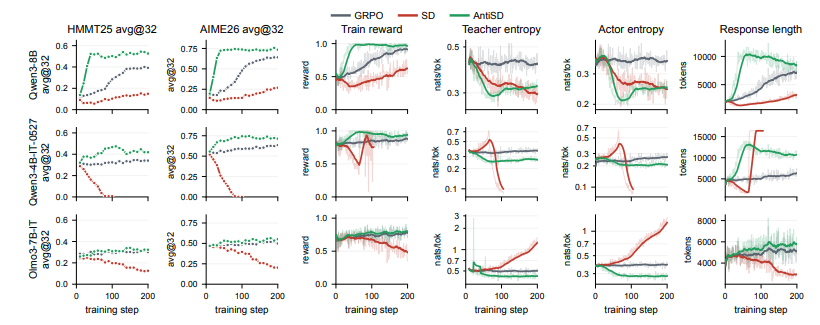

人工智能论文评审:GPT-4技术报告(GPT-4)
freeCodeCamp.org
·
