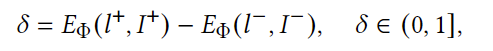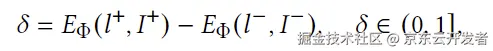Uni-Layout框架整合了布局生成与人类反馈评估,克服了现有方法的局限性。通过统一生成器和Layout-HF100k数据集,提升了布局设计的灵活性和评估准确性。动态边距偏好优化技术增强了生成与人类审美的对齐,实验结果显示其在多项任务中表现优异。
Uni-Layout框架结合了布局生成与人类反馈评估,克服了现有方法的局限性。通过统一生成器和Layout-HF100k数据集,提升了布局设计的灵活性和评估准确性,并采用动态边距偏好优化技术,实现了更好的用户偏好对齐。
本研究提出了一种名为CHARM的校准方法,旨在解决奖励模型中的偏差问题,从而提高评估的准确性和与人类偏好的相关性,促进更公平可靠的奖励模型构建。
本文探讨可解释自动事实核查中的行动性评估问题,指出现有研究缺乏有效评估方法。提出的FinGrAct框架通过明确标准和评估数据集,提高评估准确性,减少偏见,具有重要的实际应用价值。
本研究提出了MEMERAG,一个多语言端到端元评估基准,旨在解决现有评估主要集中于英语的问题。通过使用本土语言问题和多种大型语言模型生成的响应,增强了评估的准确性,实验结果表明该基准能有效识别多语言自动评估者的改进效果。
机器学习模型的泛化能力尚不明确,测试集数据泄漏会导致评估错误。新开源功能Leaky-Splits可自动检测和清理数据泄漏,从而提高模型的可信度和评估准确性。
本研究提出了一种结合检测与缓解技术的方法,针对大型语言模型中的幻觉问题。通过检索增强生成框架和负缺失信息评分系统,提高了评估准确性,Gemma2和GPT-4表现优异,为医疗等领域的应用提供了新思路。
本文探讨大型语言模型在知识获取和机器翻译评估中的应用,强调通过设计提示和反事实演示提高上下文真实性。研究表明,参考信息显著提升评估准确性,而源语言信息有时会产生负面影响。此外,提出了改进翻译质量的算法和框架,分析了源上下文与目标上下文对翻译性能的影响。
本文探讨了动作质量评估(AQA)的多任务学习方法,提出了MCoRe框架和渐进自适应多模态融合网络(PAMFN),通过结合视觉和音频信息提高评估准确性。研究表明,这些新方法在多个AQA基准测试中表现优异,解决了传统方法的不足。
本研究比较了ChatGPT和Bing Chat在检测政治信息真实性方面的能力。ChatGPT在不同语言中的评估准确性为72%,Bing Chat为67%。ChatGPT提供的输出更为细致入微,但聊天机器人的性能受到话题和来源的影响。这些发现显示了LLM聊天机器人在解决虚假信息方面的潜力,但也指出了其实现方式的差异。
完成下面两步后,将自动完成登录并继续当前操作。