

在气候预测中,简单模型可以优于深度学习
MIT News - Artificial intelligence
·

生成式人工智能模式:查询重写
Martin Fowler
·
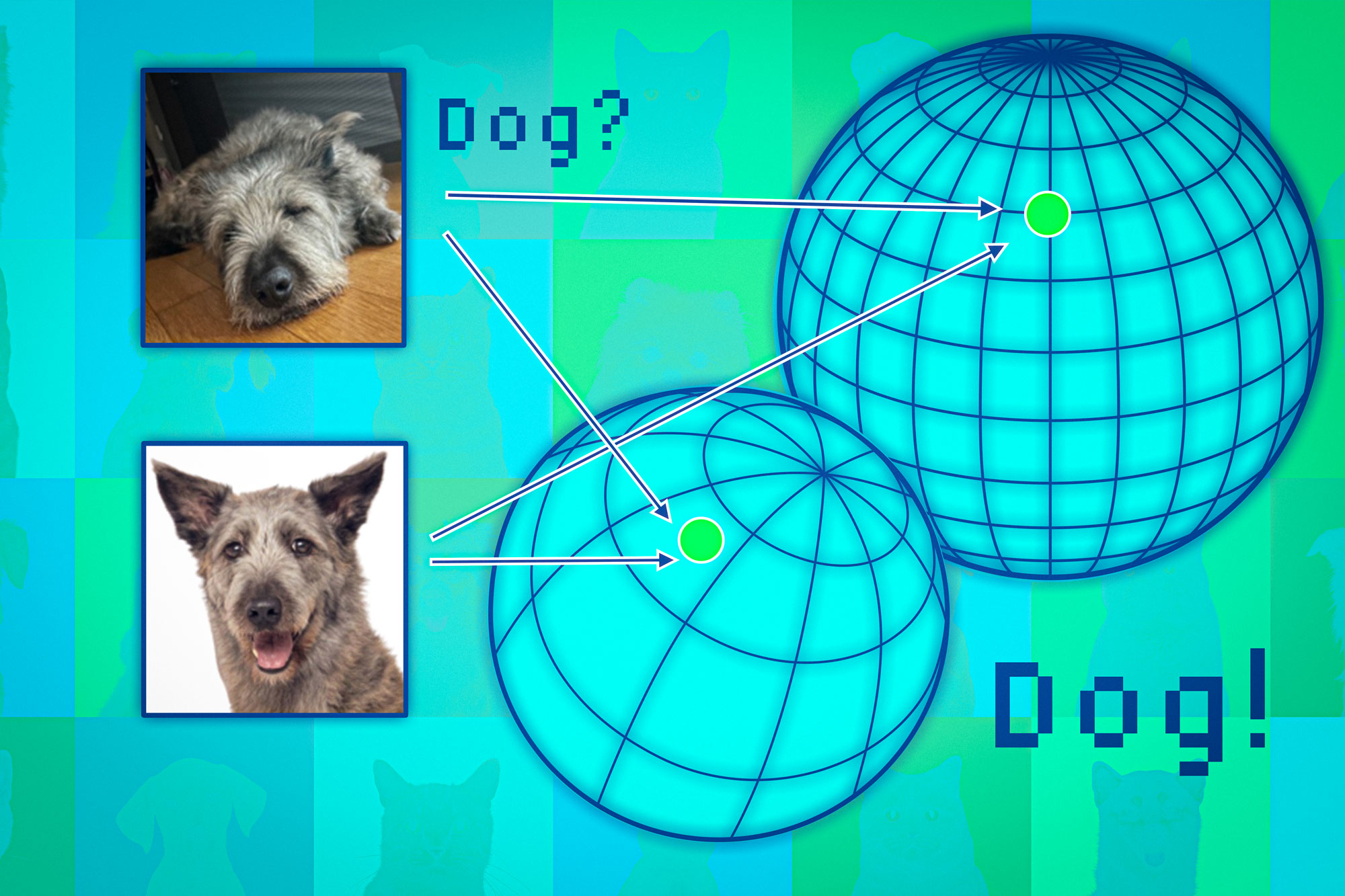
如何在部署前评估通用AI模型的可靠性
MIT News - Artificial intelligence
·

迈向稳健评估:大型语言模型时代开放领域问答的数据集和评估指标的综合分类法
Apple Machine Learning Research
·
