RubiCap是一种新型强化学习框架,通过大型语言模型生成细致的奖励信号,有效解决图像字幕生成中的多样性和泛化问题。在CapArena和CaptionQA基准测试中表现优异,超越传统方法和人类专家注释。
文章讨论了综艺节目《歌手》中对歌手评分的多维度标准,包括演唱技巧、选曲和公众形象等。评估指出不同歌手在情感表达和歌曲理解上的不足,反映节目对音乐审美的影响。
本研究通过增加多重语法错误修正参考和评分标准,丰富了韩语学习者语料库KoLLA,使其成为韩语二语教育研究的标准化资源,促进语言学习与评估。
本研究提出KOFFVQA基准,旨在解决视觉语言模型评估中的主观性和开放性不足问题。该基准包含275个问题,结合图像和10个评分标准,通过客观评估提高评分一致性和可靠性,以更好地评估不同语言模型的表现。
本文探讨了多种基于人工智能的运动质量评估(AQA)方法,包括可解释的Rubric-Informed Segmentation模型和不确定性感知评分模型(USDL)。研究表明,这些方法在运动表现评估中优于传统模型,增强了裁判的信任度,并提供了更可靠的评分依据。同时,多任务学习和半监督方法显著提高了评估准确性,推动了AI生成视频中动作质量评估的发展。
本文介绍了如何充分利用Google Classroom帮助教师和学生适应新的学习方式,包括个性化教学、使用评分标准、获取学生学习情况、提供支持、使用互动问题视频等。还介绍了导入和共享资源,以及灵活安排作业和评分。
本文讨论了有效进行行为面试的方法,强调准备的重要性。建议花费2小时设计面试问题和评分标准,以便更好地评估候选人。面试时应专注于1-3个相关技能,深入挖掘细节,避免模糊回答。建立评分标准有助于明确评估标准,提升面试效果。
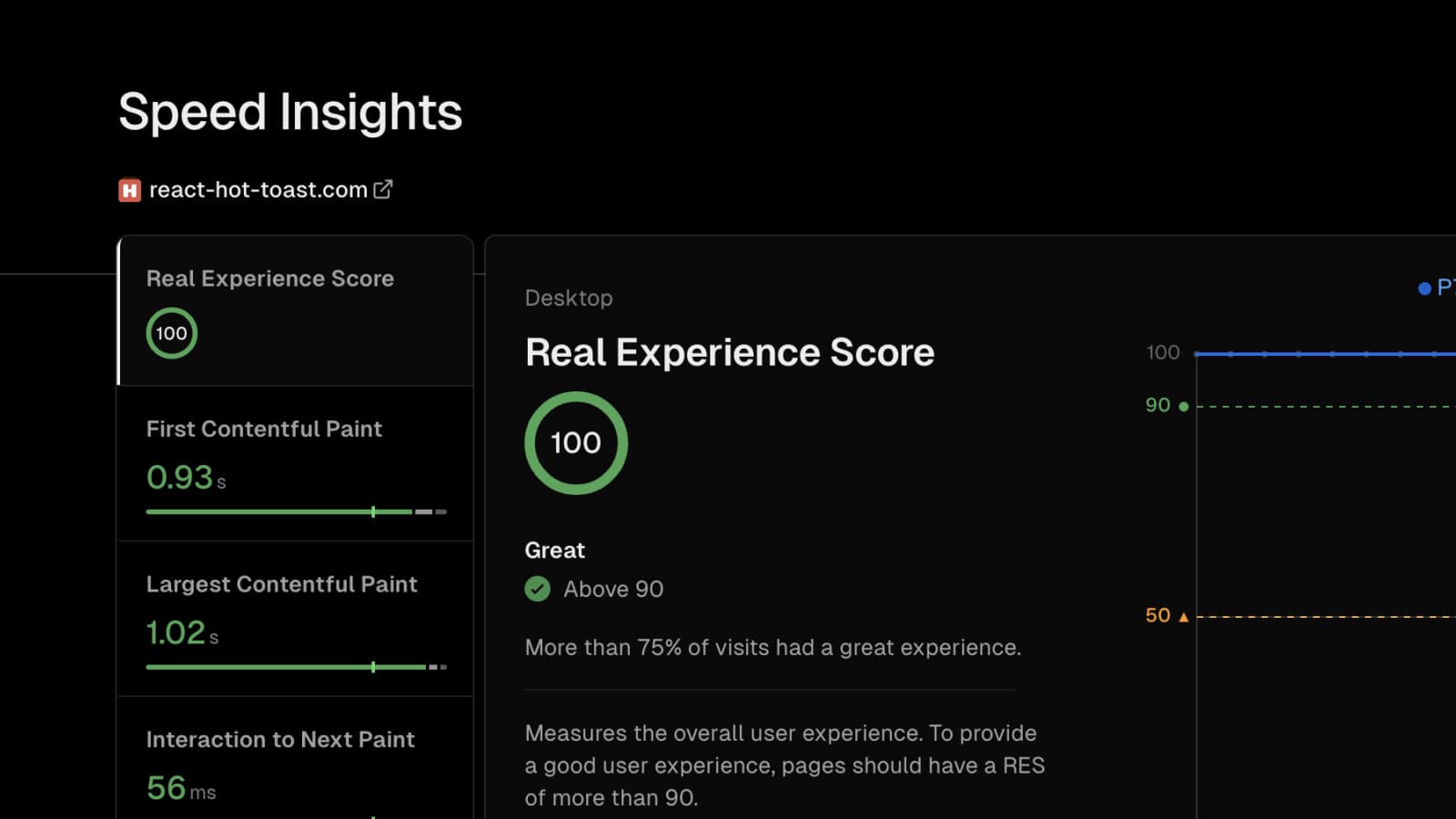
Speed Insights 更新了网站性能测量工具,支持所有前端框架,提供第一方数据处理,更新评分标准,增加区域性能数据展示,测量首次字节时间(TTFB),并提供高级定制功能。所有计划均可使用此工具。
首届开源AI游戏开发大赛将于7月7日至9日举行,参赛者需使用至少一个开源AI工具,评分标准为趣味性、创意和主题,评选前十名。大赛旨在展示AI为游戏开发者带来的无限可能性。
本文介绍了英语翻译的评分标准和考研翻译能力要求,评分依据包括译文是否扭曲原意、多个译法的处理及错别字的扣分规则。翻译技巧强调理解原文、流畅表达和复杂句的拆分翻译方法,提供了具体的拆分和组合技巧。
完成下面两步后,将自动完成登录并继续当前操作。