

TPU开发者中心:高性能AI平台的技术评审
mongona news
·

九位评审,两个有效投票:相关错误削弱大型语言模型评估小组
Apple Machine Learning Research
·

如何赢得黑客马拉松:评审桌上的笔记
The JetBrains Blog
·

人工智能论文评审:链式思维提示激发大型语言模型的推理能力
freeCodeCamp.org
·


人工智能论文评审:通过人类反馈训练语言模型以遵循指令(InstructGPT)
freeCodeCamp.org
·

人工智能论文评审:GPT-4技术报告(GPT-4)
freeCodeCamp.org
·

人工智能论文评审:语言模型是少量学习者(GPT-3)
freeCodeCamp.org
·

人工智能论文评审:语言模型是无监督的多任务学习者(GPT-2)
freeCodeCamp.org
·

AI论文评审:通过生成预训练(GPT-1)提升语言理解
freeCodeCamp.org
·

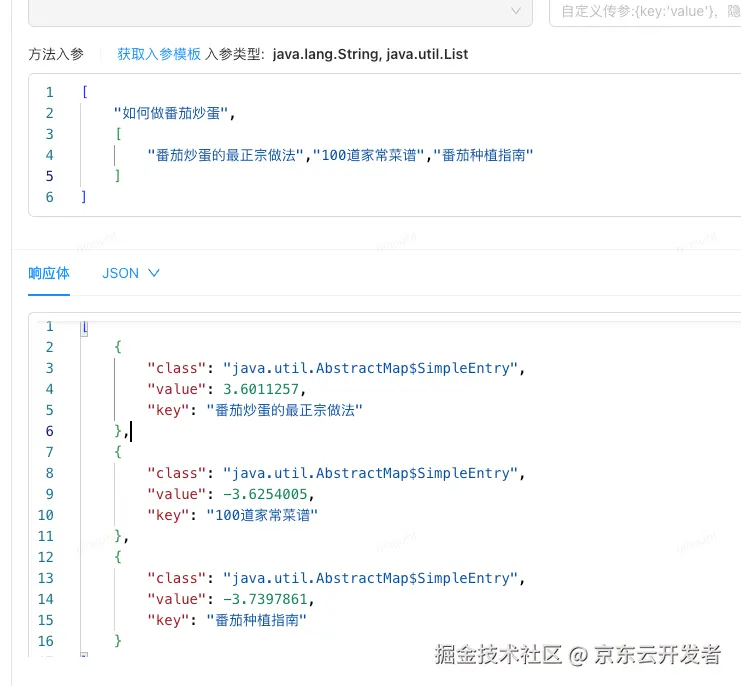
基于知识工程&JoyAgent双RAG的智能代码评审系统的探索与实践
京东科技开发者
·

