

粤港澳大湾区大数据研究院词元经济联合创新应用中心在深圳揭牌成立
全球TMT-美通国际
·
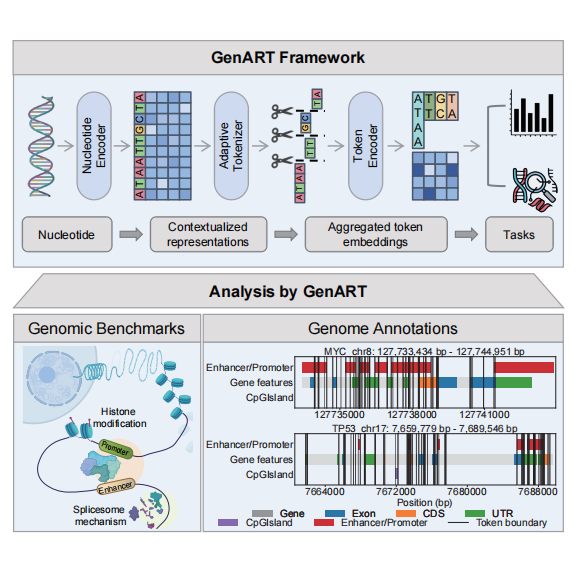
从K-mer到自适应词元:厦门大学林琛团队让AI自动学习「基因功能边界」
HyperAI超神经
·



软通动力宣布“北京壹号词元工厂”正式投入运行
全球TMT-美通国际
·
从Token到词元:全模态时代的基模与交互入口
量子位
·

是时候给 AI 一套配得上这个时代的中文了
爱范儿
·
