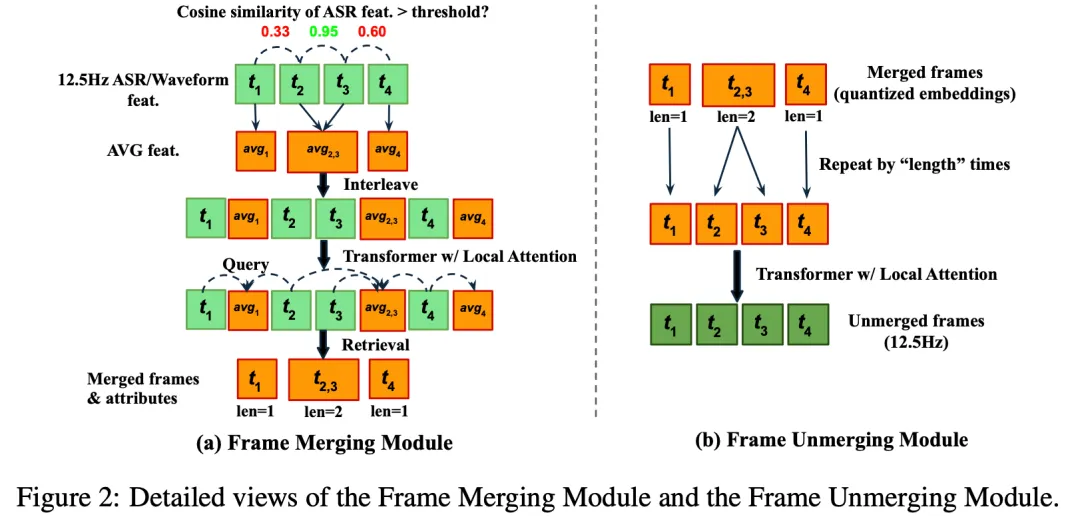
FlexiCodec是一种新型音频编解码器,支持低于10Hz的超低帧率,旨在提高语义信息的保留。通过动态帧率、ASR引导的语义和可控帧率,FlexiCodec在音频质量和处理速度上表现优异,适用于多种应用场景。
本研究提出了一种新型少样本编码解码方法,解决了传统视频监控语义解码对大量样本的依赖。通过提取草图作为语义信息并结合图像翻译网络,显著提升了视频重构性能,降低了存储和传输成本。
本研究提出了一种新方法,结合空间和语义信息,提升面部深伪检测的泛化能力。该方法通过特征正交分离策略,在Celeb-DF和DFDC数据集上分别提高了5%和7%的准确率,优于现有技术。
本研究提出了一种新的生成语义通信(GSC)范式,旨在应对人工通用智能(AGI)背景下语义信息高效传输的挑战,展示其在AGI应用中的优势,为实际应用奠定基础。
本研究提出了一种新方法,针对商业黑箱视觉语言模型(LVLMs)进行有效攻击,成功率超过90%。通过在局部区域编码明确的语义信息,显著提高了攻击效果,解决了传统方法的不足。
本研究提出VLM-E2E框架,旨在解决现有自主驾驶系统在复杂环境中无法有效利用语义信息的问题。该方法通过融合视觉语言模型与文本表示,提高了语义监督,模拟人类驾驶行为,并在nuScenes数据集上显著提升了性能。
本研究探讨了语言模型重排名器在检索增强生成任务中的表现不足,特别是在处理语义信息方面的局限性。提出了一种基于BM25的新分离度量,揭示了重排名器在词汇不相似性方面的错误,并探讨了提升其性能的方法,强调了对更具对抗性评估数据集的需求。
本研究提出了一种轻量级方法——重写样本化MLP(RSMLP),用于处理不完整话语重写任务。通过下采样策略提取潜在语义信息,从而提升理解能力。实验结果表明,RSMLP在数据集和实际应用中表现优异。
本研究提出了GraphGPT-O,旨在解决多模态大语言模型在处理多模态属性图时整合关系和语义信息的问题。该方法通过线性化变体和分层对齐器,在多个领域的数据集上表现优异,展现出重要的应用潜力。
本研究提出了一种常识知识提取的文本增强方法(TECO),旨在提升多模态意图识别的性能。该方法通过提取知识关系,丰富文本上下文信息,有效融合语言与非语言模态,解决了语义信息提取和模态融合的挑战。
本研究提出了一种名为InvDiff的偏差消减框架,旨在解决扩散模型在生成高质量图像时的偏差与不平衡问题。通过新的去偏训练目标和轻量级可训练模块,InvDiff能够自动保留语义信息,生成无偏图像,同时保持图像质量。
本研究提出了一种名为'对比驱动医学图像分割'的框架,旨在解决医学图像分割中前景与背景模糊边界的问题。该方法通过引入对比训练策略和语义信息解耦模块,在低对比度和复杂场景下表现出更强的鲁棒性,实验结果显示其在多个数据集上具有先进性能和广泛适用性。
LST(无损语义树)是OpenRewrite的核心,确保在代码解析时保留所有信息,包括格式和类型。与传统AST相比,LST提供更精细的变更控制和丰富的语义信息,使代码重构和自动化变更更加精准。理解LST结构对有效的代码调整至关重要。
本研究提出了一种新型超像素信息隐式神经表示(S-INR),旨在解决隐式神经表示在多维数据恢复中的局限性。S-INR通过使用广义超像素替代传统像素,有效挖掘超像素间的语义信息,展现出更优的应用效果。
本文介绍了在NeurIPS 2024自监督学习研讨会上接受的IJEPA模型,该模型为图像表示学习提供了一种新方案。IJEPA通过在潜在空间中进行预测,捕捉有用的语义信息,且依赖于精心设计的上下文和目标窗口。研究表明,结合上下文和目标窗口的位置可以提升模型在图像分类基准数据集上的表现和鲁棒性。
本研究重新实现了五种扩散模型,解决了训练过程中的关键组件缺失问题。提出的新条件机制有效解耦了语义信息与控制元数据,显著提升了在ImageNet-1k和CC12M数据集上的图像生成性能。
本文探讨了大型语言模型(LLMs)的推理能力及其在语义理解中的表现。研究发现,LLMs在逻辑推理和符号推理方面存在限制,推理依赖于训练数据的表面模式。提出了SENSE方法,通过嵌入语义提示提升LLM性能,强调整合语义信息的重要性。
本文介绍了一种新型图像超分辨率方法ACDMSR,利用预训练的扩散模型和可控特征模块,克服了固定尺寸的限制。该方法通过减少扩散步骤,提高了推理速度和图像质量,实验结果表明其性能优于现有方法。此外,XPSR框架结合多模态大语言模型,增强了语义信息提取,生成高保真度图像。
本文介绍了一种新方法,通过感知系统提供场景中物体的几何和语义信息,以提升机器人抓取效率。研究表明,该方法在动态环境中实现实时重建,抓取成功率超过90%。利用深度传感器和卷积神经网络,显著提高了复杂场景中的抓取规划效果。
本文介绍了一种基于三维激光雷达和神经网络的建图与定位方法,能够有效滤波运动物体并提取语义信息。实验结果表明,该方法性能优于传统几何约束方法。此外,Scene-LLM模型增强了3D室内环境中的交互能力,支持复杂智能体的规划与定位。其他模型如LSeg和SemiVL在语义分割和导航系统中也表现出显著的性能提升。
完成下面两步后,将自动完成登录并继续当前操作。