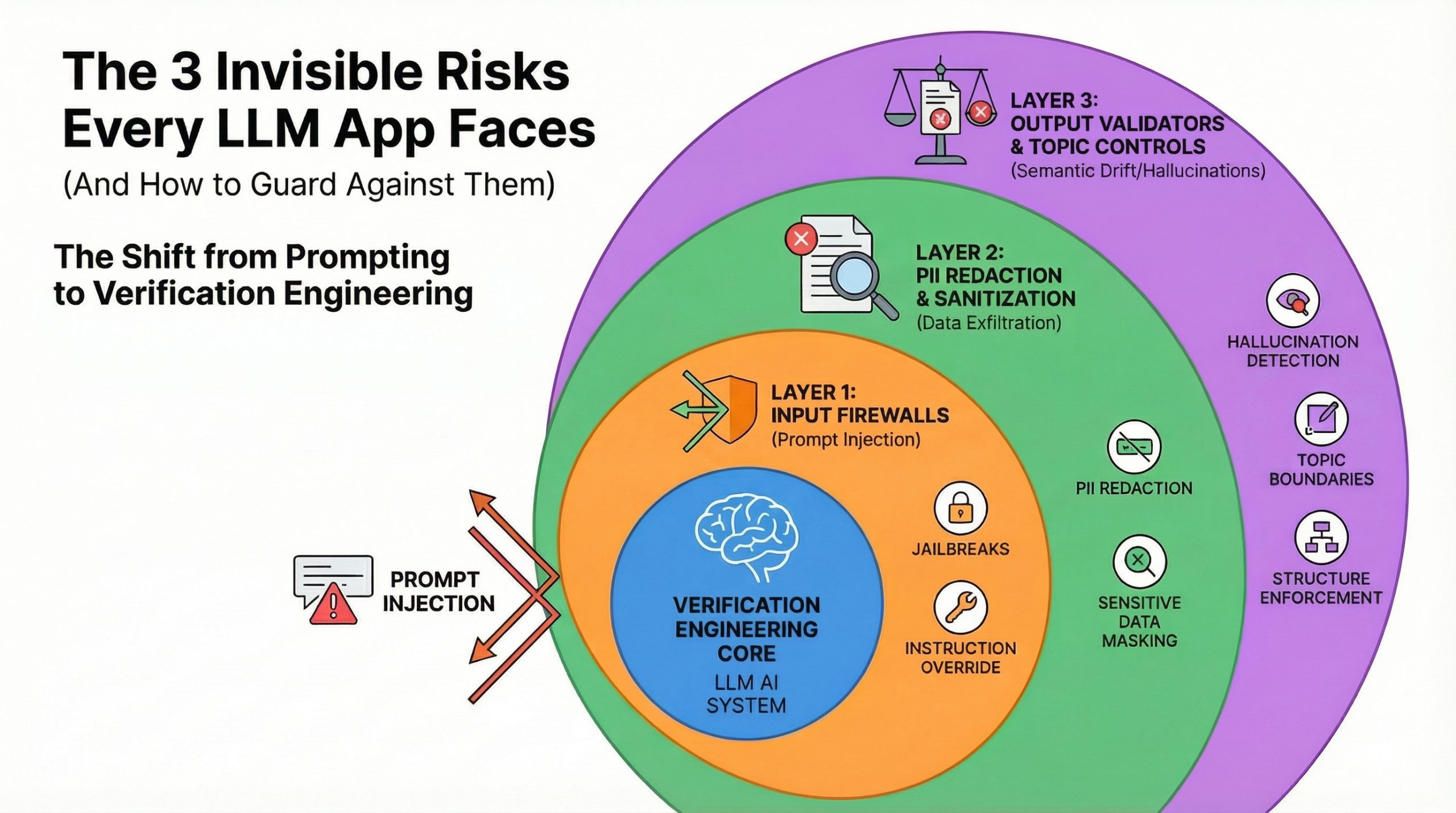
大型语言模型应用面临三大隐性风险:提示注入、数据外泄和语义漂移。提示注入可能导致用户操控AI行为,数据外泄可能泄露敏感信息,语义漂移则使AI生成不准确或不相关的回答。为应对这些风险,建议使用输入防火墙、PII检测工具和输出验证器等安全措施,以确保AI的安全性和可靠性。
本研究提出了一种跨语言一致性(CLC)框架,旨在解决多语言训练语料中的语言偏差引起的语义漂移和逻辑不一致问题。通过多语种推理路径集成和多数投票,CLC显著提升了大语言模型的推理能力,实验结果显示准确率提高了9.5%至18.5%。
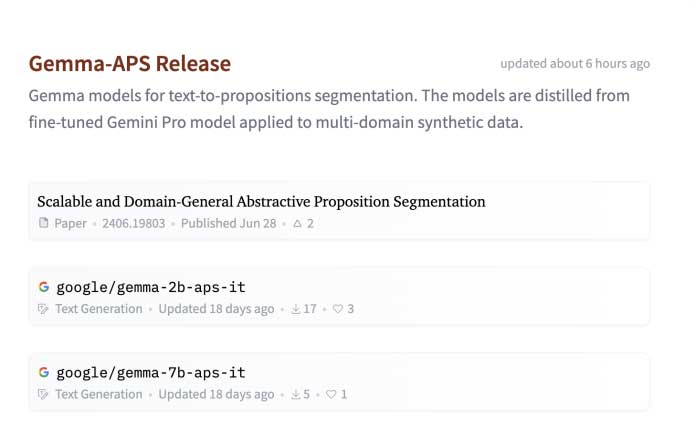
Google AI 发布了 Gemma-APS 模型,可以将复杂文本分割为易于管理的单元。该模型通过多领域数据训练,适用于情感分析和信息检索等任务,具有高准确性和计算效率,减少语义漂移风险。这标志着文本分割技术的重大进步。
本文介绍了多种实体集扩展方法,包括基于生成式预训练语言模型的GenExpan框架和多模态模型MultiExpan,均在多个数据集上表现优异。此外,研究提出了独立于语料库的ESE范例和Set-CoExpan框架,有效解决了语义漂移问题,展现出显著的扩展性能。
完成下面两步后,将自动完成登录并继续当前操作。