
每个大型语言模型应用面临的三大隐性风险(及其防范措施)
内容提要
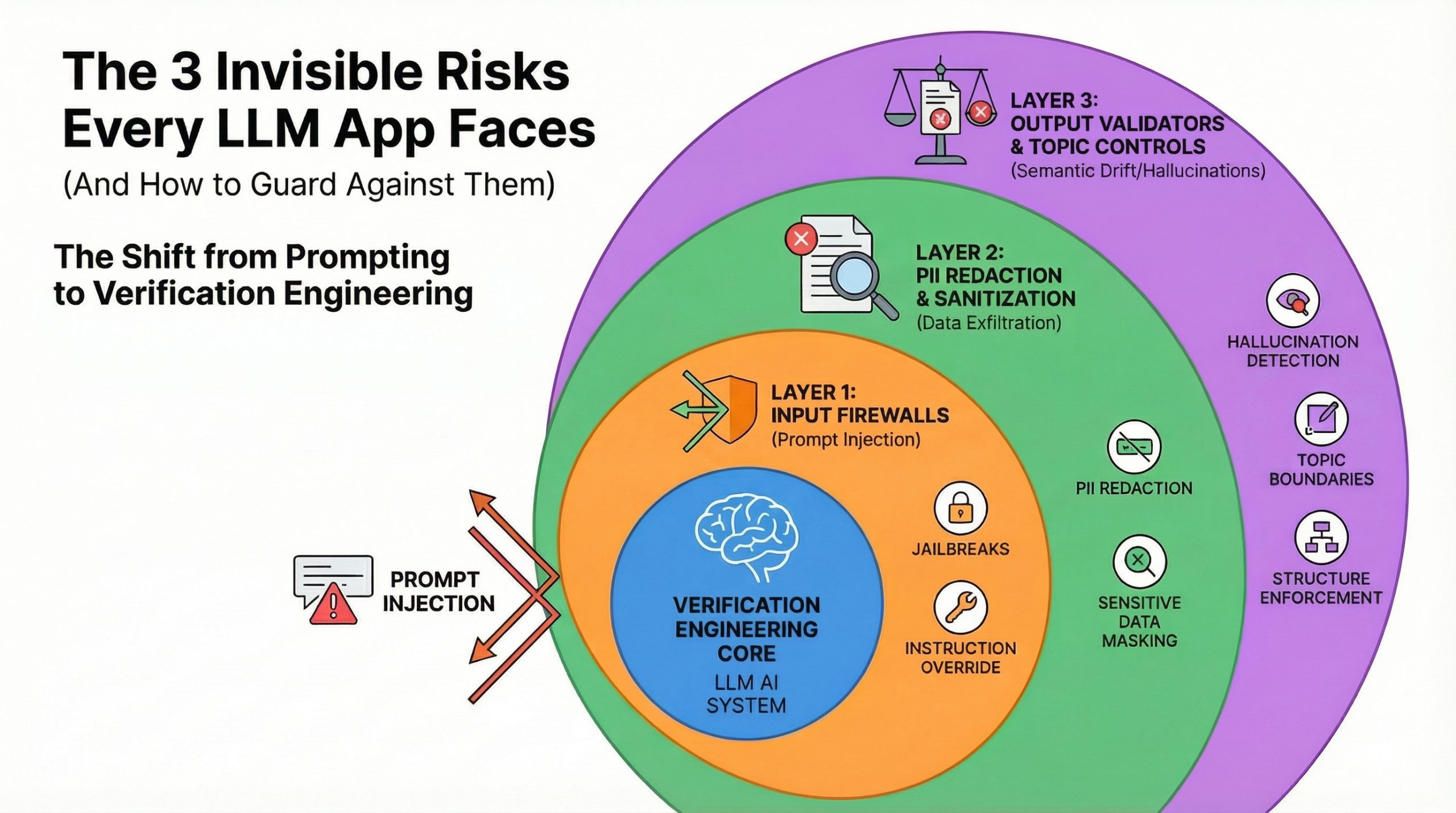
大型语言模型应用面临三大隐性风险:提示注入、数据外泄和语义漂移。提示注入可能导致用户操控AI行为,数据外泄可能泄露敏感信息,语义漂移则使AI生成不准确或不相关的回答。为应对这些风险,建议使用输入防火墙、PII检测工具和输出验证器等安全措施,以确保AI的安全性和可靠性。
关键要点
-
大型语言模型应用面临三大隐性风险:提示注入、数据外泄和语义漂移。
-
提示注入可能导致用户操控AI行为,用户可以通过嵌入指令来覆盖应用的预期行为。
-
数据外泄可能泄露敏感信息,包括个人身份信息(PII)和公司机密数据。
-
语义漂移使AI生成不准确或不相关的回答,可能导致用户信任度下降。
-
为应对这些风险,建议使用输入防火墙、PII检测工具和输出验证器等安全措施。
延伸解读
提示注入的潜在威胁
提示注入是大型语言模型应用中的一个重要风险,用户可以通过嵌入指令来操控AI的行为。这种攻击方式不仅限于简单的指令覆盖,还可能通过复杂的角色扮演和多步骤操控来实现。因此,开发者需要特别关注输入防火墙的实施,以防止此类攻击对应用的影响。
数据外泄的隐患
数据外泄是大型语言模型应用中常见的风险,尤其是在处理个人身份信息(PII)时。AI可能在无意中泄露敏感信息,导致严重的隐私问题。使用PII检测和消毒工具可以有效降低此类风险,确保用户数据的安全性。
语义漂移的影响
语义漂移可能导致AI生成不准确或不相关的回答,严重时会损害用户信任。特别是在医疗和金融等领域,错误信息的传播可能带来法律和合规风险。因此,实施输出验证工具和主题控制是确保AI生成内容准确性的关键措施。
延伸问答
大型语言模型应用面临哪些隐性风险?
大型语言模型应用面临三大隐性风险:提示注入、数据外泄和语义漂移。
什么是提示注入,如何影响AI的行为?
提示注入是指用户在输入中嵌入指令,可能覆盖应用的预期行为,导致AI执行不当操作。
数据外泄的风险如何发生?
数据外泄可能通过AI无意中透露训练数据中的敏感信息或在检索增强生成过程中分享公司数据库的信息。
语义漂移是什么,为什么会造成用户信任度下降?
语义漂移是指AI生成不准确或不相关的回答,可能导致用户对AI的信任度下降。
如何防范提示注入风险?
可以使用输入防火墙来分析用户提示,检测并阻止恶意输入,从而防范提示注入风险。
PII检测工具的作用是什么?
PII检测工具用于自动识别和屏蔽敏感信息,防止在用户交互中泄露个人身份信息。
