

ParaRNN:大规模非线性递归神经网络,可并行训练
Apple Machine Learning Research
·

数据质量的幻觉:重新思考基于分类器的质量过滤在大规模语言模型预训练中的应用
Apple Machine Learning Research
·
FS-DFM:基于少步扩散语言模型的快速准确长文本生成
Apple Machine Learning Research
·
基于变换器的自回归流在连续空间中的灵活语言建模
Apple Machine Learning Research
·
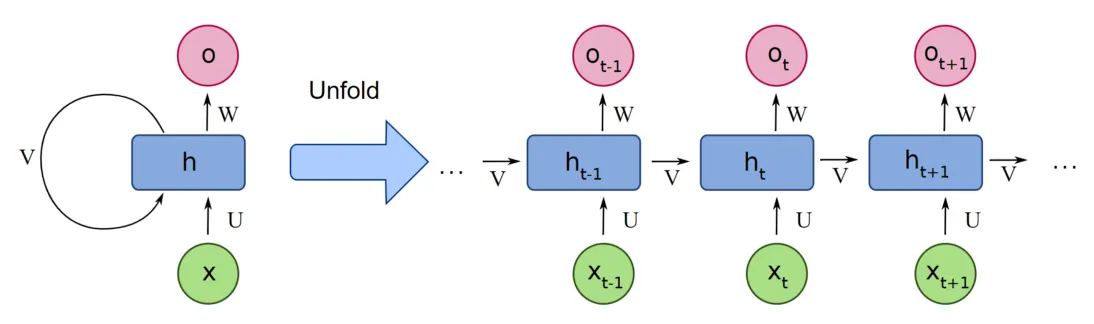
深入理解大模型 1:Transformer,大模型的基石
木鸟杂记
·
目标混凝土评分匹配:离散扩散的整体框架
Apple Machine Learning Research
·
通过自回归模型的适应扩展扩散语言模型
Apple Machine Learning Research
·




