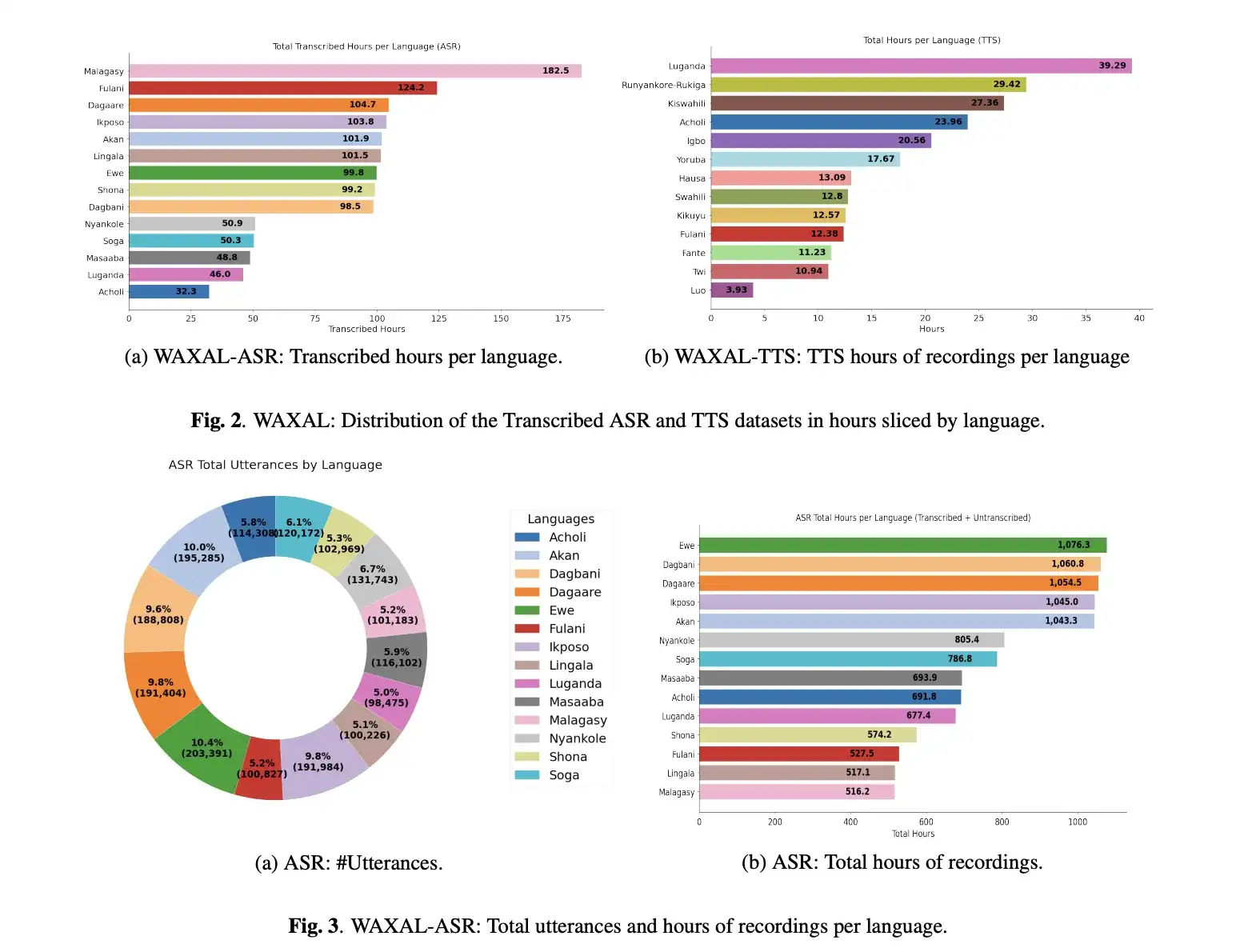
WAXAL是一个开放的多语言语音数据集,涵盖24种非洲语言,专为自动语音识别(ASR)和文本转语音(TTS)设计。ASR部分通过图像提示自然采集语音,TTS部分在录音棚中高质量录制,确保语音一致性。
近年来,AI语音技术迅速发展,依赖于高质量、多样化的语音数据集。这些数据集通过数据收集、预处理和训练,帮助AI生成自然语音,广泛应用于虚拟助手和有声读物等领域。随着技术进步,语音AI的功能和个性化不断提升,确保数据质量和多样性至关重要。
本研究提出了Paralinguistic Speech Captions(ParaSpeechCaps)数据集,解决了大规模语音数据集风格标签不足的问题。通过结合多种文本与语音嵌入技术,自动扩展了59种风格标签的数据集。微调TTS模型后,语音风格一致性和自然度显著提高,展示了研究的潜在影响。
本研究评估了现有语音数据集在团队协作问题解决中的适用性,填补了机器学习模型开发中的数据缺口,并提出了未来数据集设计的要求,为提高协作问题解决效果提供了理论基础。
FLEURS是一个包含102种语言的语音数据集,旨在推动多语言自动语音识别和翻译技术的发展。文章探讨了评估指标的鲁棒性及其在图像描述和语音任务中的应用,提出了新方法以提高评估效果,并指出无参考指标的不足。
MyVoice是一个收集阿拉伯语言方言的语音数据集的众包平台,允许参与者选择城市/国家级的细粒度方言,并录制显示的话语。该平台整合了质量保证系统,管理员可以添加新数据或任务,并将其显示给贡献者,促进收集多样化和大量的阿拉伯语言数据的协作努力。
ADReSS Challenge是一个用于比较自动识别老年痴呆症语音的共享任务,提供了基准的语音数据集和两个认知评估任务。该挑战旨在为语音和语言老年痴呆症研究社区提供一个综合方法比较的平台,为未来的研究和临床应用提供线索。
本文介绍了一种使用深度卷积神经网络作为结构变分近似的推理网络的无监督模型ConvDMM,它使用非线性发射和转移函数模型的高斯状态空间模型。ConvDMM在大规模语音数据集上进行训练,产生的特征在线性电话分类和在WSJ数据集上的识别方面显着优于多个自我监督的特征提取方法,并且可以与其他自我监督的方法相辅相成,进一步提高了结果。在少量标记训练示例的极低资源之下,ConvDMM功能使得学习更好的电话识别器比任何其他功能。
该文章介绍了Expresso数据集,用于无文字语音合成,包括朗读语音和即兴对话。作者通过表达性再合成基准评估了不同自我监督离散编码器的合成质量,并探讨了质量、比特率和对说话人和风格的不变性之间的权衡。所有数据集、评估指标和基线模型均为开源。
完成下面两步后,将自动完成登录并继续当前操作。