钉钉推出DingTalk A1 Pro,售价1299元,专为商务人士设计。该设备配备2980mAh电池,支持180小时录音和反向充电,搭载专业麦克风,能在嘈杂环境中清晰录音。用户可享受6个月语音转文字服务,支持多语种翻译,产品轻薄便携,触控操作直观,适合各种工作场景。
文章讨论了多个技术主题,包括Sam Burns设计的混凝土笔记本支架、Bram Cohen对“氛围编码”的批评、电影《低能时代》的现实相似性、开源游戏《韦斯诺斯之战》,以及Ghost Pepper语音转文字应用、GLM-5.1 AI模型的长时任务处理能力和阿波罗11号导航计算机中的漏洞。此外,作者还分享了将博客CDN从Cloudflare迁移至Bunny.net的过程,以及Adobe未经用户同意修改系统文件的隐私争议。
Typeless是一款新型语音转文字输入法,旨在提高与AI的沟通效率。它简化输入过程,帮助用户清晰表达想法,特别适合需要频繁修改文本的场景。与传统输入法不同,Typeless更注重信息整理与精准传达。
Mistral AI 于 2 月 4 日发布了 Voxtral Transcribe 2 系列语音转文字模型,包括面向批量处理的 Voxtral Mini Transcribe V2 和实时转录的 Voxtral Realtime。Voxtral Realtime 具有低于 200 ms 的延迟,支持 13 种语言。定价方面,Mini Transcribe V2 每分钟 0.003 美元,Realtime 每分钟 0.006 美元。
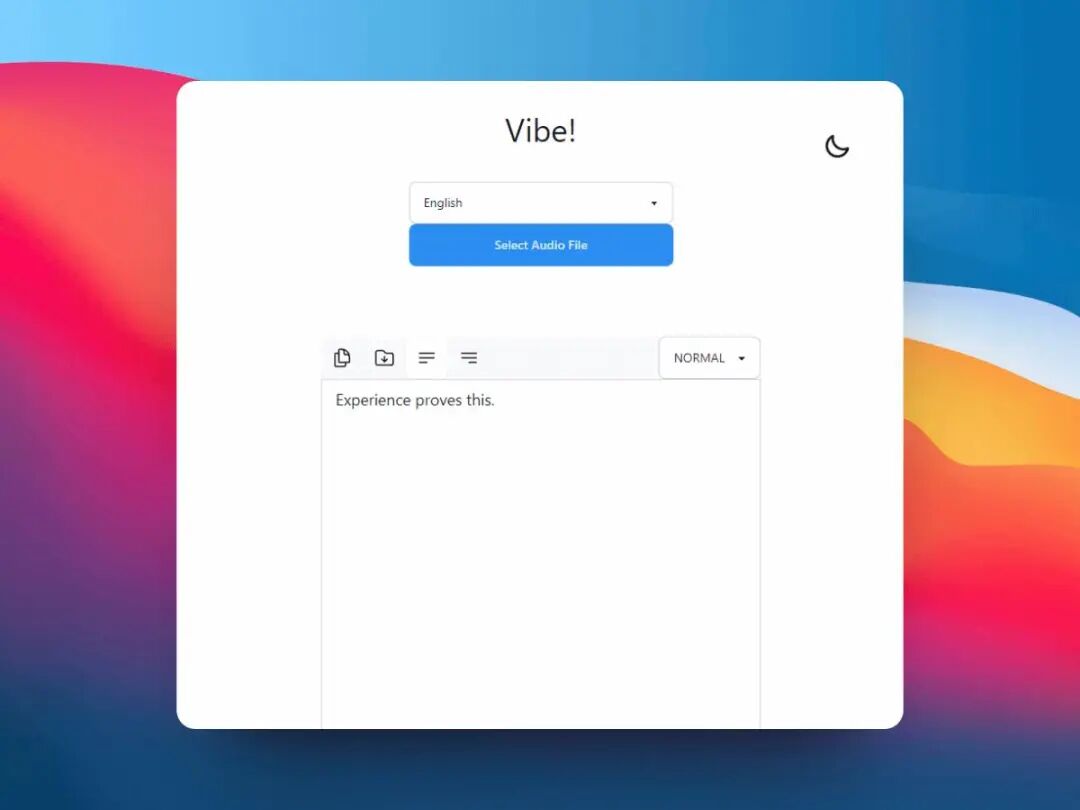
Vibe是一个开源的离线语音转文字工具,基于OpenAI Whisper模型,支持多语言转录和字幕导出,具备GPU加速,确保隐私安全。它可处理音频和视频文件,支持批量处理和在线媒体转录,完全免费。
Pebble 创始人 Eric Migicovsky 推出了售价 75 美元的智能戒指 Index 01,主要功能为 AI 记事和录音,支持语音转文字,但需按住按钮。戒指具备生活防水功能,不适合游泳,且不具备健康追踪能力,所有数据存储在移动设备上。
VoiceInk 是一款 macOS 语音转文字应用,具备99%准确率的离线转录功能,注重隐私保护。WeKnora 是基于大语言模型的文档理解框架,支持多种格式的内容提取。Strix 是开源的AI渗透测试代理,能够动态检测安全漏洞。adk-web 简化AI代理的开发,LEANN 是高效的向量数据库,专注于私密检索。
Get笔记是一款AI驱动的智能笔记工具,用户已超过150万,其中一半为新用户。其核心功能包括语音转文字和知识库管理,强调用户共创与需求投票。团队专注于解决用户痛点,提升用户体验。
Handy是一款完全离线的开源语音转文字应用,支持多种操作系统,注重隐私,使用本地语音识别,简单易用,具备静音检测和模型优化功能。
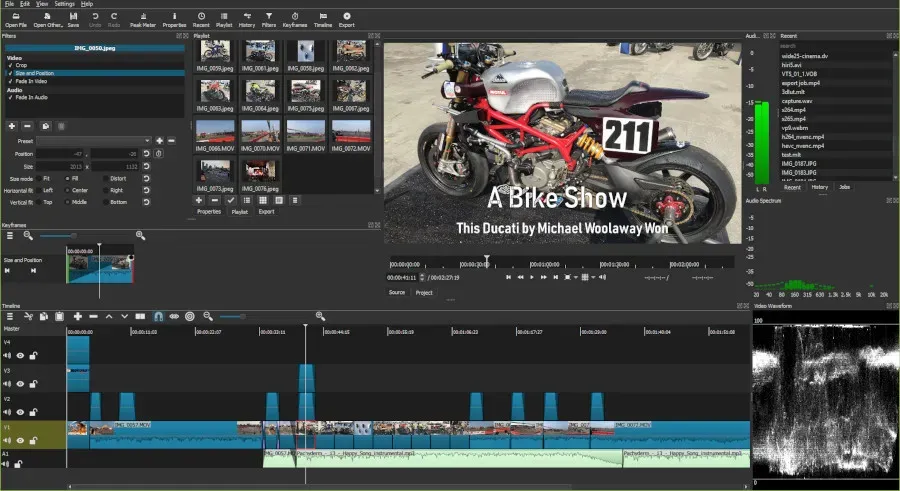
Shotcut 25.10 测试版发布,新增 AI 功能,包括实时文本转语音和语音转文字,支持多语言和多种语音。更新还包含视频滤镜及其他修复。
epicenter 是一个开源应用生态系统,用户可以管理数据并选择模型,提供本地语音转文字工具和助手,强调开放性与可定制性。mcp 服务器利用 AWS 服务,支持多种客户端。virgo 是 System76 笔记本的电气设计库,chatgpt-spring-boot-starter 支持 ChatGPT 聊天功能。
Anna's Archive团队致力于保护文化遗产,发布了历史上最大的书籍元数据集合,并呼吁志愿者参与。Hyperclay简化网页开发,Claudia为Claude Code提供桌面应用。ArchiveTeam完成了goo.gl短链接的归档。谷歌承认在澳大利亚的反竞争行为。Whispering是一个强调用户数据隐私的开源语音转文字应用。
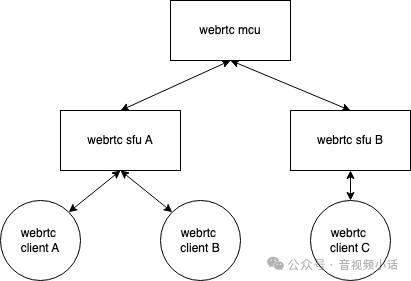
本文介绍如何利用AI技术为WebRTC视频会议实时生成字幕,提升会议体验。通过音频流处理、语音活动检测和语音转文字技术,实现实时字幕功能,未来可实现同声传译。
雅婷逐字稿是一款语音转文字工具,提供时间戳、可编辑逐字稿和高亮功能,帮助研究者分析访谈内容。尽管某些功能需改进,其强大的转录能力值得尝试。用户可免费注册获得300分钟试用,之后需付费。
AI帮助个人开发者过滤垃圾语音,降低内容审核成本。陌生人闹钟App可在节假日自动关闭闹钟,讯飞听见和搜狗听写提供语音转文字功能,提升用户体验。
本文讲解如何使用HTML、JavaScript和CSS创建语音转文字应用。通过SpeechRecognition API,将语音实时转为文本。步骤包括设计HTML结构、用JavaScript实现功能、用CSS美化界面。用户可根据需求调整布局和样式。
墨问便签是一款专为创作者设计的微信小程序,支持文字、语音、图片等多种记录方式,适合作家和自媒体人。它强调创作与生活的结合,具备语音转文字和隐私设置等功能,方便快速记录和分享内容。
本研究利用多模态深度学习架构进行欺诈检测,提升了检测准确度。通过分析伪造声音和音频特征,提出了新的数据集和方法,揭示了现有模型的局限性,并呼吁改进语音转文字服务中的幻觉问题,以确保公平性。
本文探讨了在成本敏感情况下,如何自动选择错误修正的位置和大小,以最大化修正数量,并提出动态更新框架以训练纠错成本模型。研究还介绍了新的语音转文字任务及其改进的转录质量方法,展示了跨模态融合技术在自动语音识别中的应用,显著提升了效率和准确性。
本文介绍了几款独立开发的产品及其推广经验,包括Supa Screenshots浏览器插件、Letterly语音转文字应用、SocialStats动画视频/GIF互动工具和CompressX视频图片压缩应用。作者分享了这些产品在不同平台上的推广策略和效果,并提供了一些建议。
完成下面两步后,将自动完成登录并继续当前操作。