


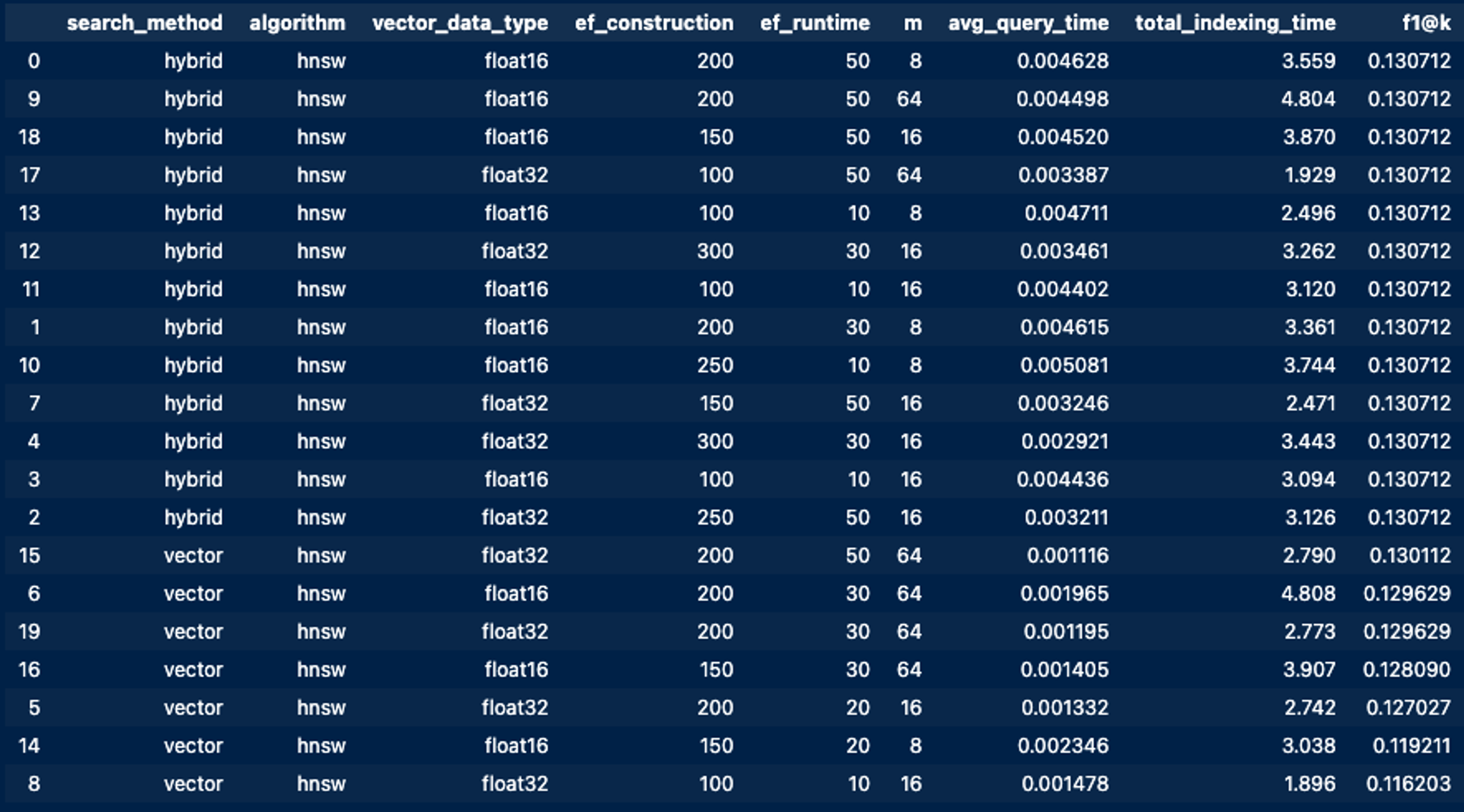
检索优化器:贝叶斯优化
Redis Blog
·
大型语言模型微调经验
informal
·

人工智能术语
DEV Community
·
斯坦福CS336:从零开始的语言建模 | 2025年春季 | 架构与超参数
Josherich的博客
·




