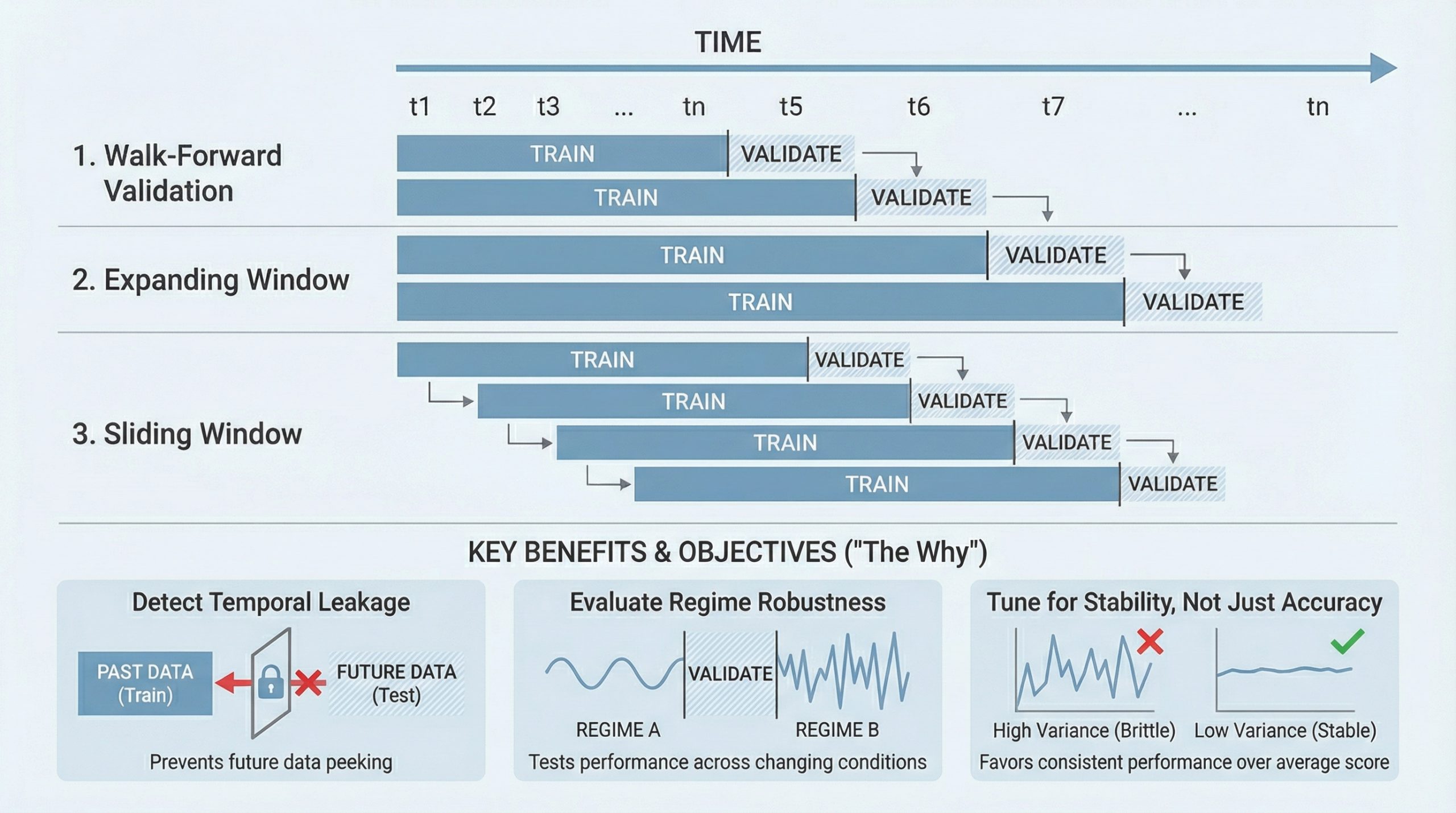
本文介绍了五种交叉验证方法,以提升时间序列模型的性能。这些方法包括前向验证以模拟真实部署、比较扩展和滑动窗口以测试记忆深度、检测时间数据泄漏、评估模型在不同状态下的稳健性,以及基于稳定性调整超参数。这些策略有助于提高模型在实际应用中的可靠性,避免过拟合和数据泄漏。
本研究提出了一种名为MR.Q的统一无模型深度强化学习算法,旨在解决现有算法对特定基准和超参数调整的依赖。该方法通过模型基础表示近似线性化价值函数,在多样任务中展现出竞争力性能,为通用无模型深度强化学习奠定基础。
AIxiv专栏报道了一种新指标模态融合率(MIR),用于评估多模态大模型(MLLM)预训练的模态对齐质量,克服了传统方法的不稳定性。研究表明,MIR与下游测试性能正相关,适合用于超参数调整和训练策略选择。
本文介绍了五种提升语言模型响应的方法:提示工程、检索增强生成、模型微调、超参数调整和模型压缩。通过优化提示、增加上下文、个性化模型和调整关键参数,可以显著提升模型性能。
本文研究了深度学习中损失函数的性质,分析了Hessian矩阵的谱特征,揭示了高维非凸优化的规律。研究表明,深度神经网络的泛化能力与损失函数的局部最小值及优化方法密切相关,并提出了新的正则化方法以提高模型性能。此外,探讨了神经崩溃现象及其解决方案,强调了超参数调整对优化景观的影响。
优化机器学习算法的关键技巧包括准备和选择正确的数据,调整超参数,实施交叉验证,使用正则化技术和集成方法。这些技巧可以提高模型性能和泛化能力,应对现实挑战。
本文提出了多种提高对抗攻击效率的方法,包括新的初始化策略、方差调整、在线增强和自适应自动攻击。这些方法在多个模型上测试,显著提升了鲁棒性和攻击成功率,尤其在对抗训练和超参数调整方面表现优越。
本研究提出了一种通过最大更新参数化(muP)解决大规模语言模型超参数调整的新方法。研究表明,muP在不同模型间实现了有效的超参数迁移,特别是在Transformer和ResNet上表现优异。通过优化学习率和超参数,显著提升了模型的泛化能力。
本文研究了自然语言输入决策中的不确定性,提出了CDT框架用于在线超参数调整,改进了Thompson Sampling算法以解决逻辑上下文bandits问题,并介绍了QTA算法以提高样本效率。此外,研究还探讨了基于模型的强化学习算法H-UCRL,展示了其在探索中的优势和广泛适用性。
研究表明,通过跨语言调整指令和数据获取方法,可以显著改善大型语言模型在未知任务上的性能。指令调优提升了模型的零样本表现,强调了语言一致性和超参数调整的重要性。对比指令调优方法(CoIN)通过最大化语义等效指令的相似性,进一步提高了模型的稳健性和准确率。
本研究提出了一种新型卷积神经网络架构Sequencer,结合LSTM以建模长距离依赖,表现优异。同时介绍了xLSTM和LiteLSTM模型,优化了LSTM的计算组件,提高了大数据学习效率,适用于物联网和医学数据。研究还分析了LSTM的关键组件,并提供了有效的超参数调整指导。
本研究系统综述了机器学习在持续集成中的应用,涵盖数据工程、特征工程和超参数调整等方面,强调需进一步研究以推动技术发展。同时探讨了机器学习开发中的挑战及解决方案,指出现有环境缺乏指导,需适应软件工程最佳实践。
本文介绍了多种贝叶斯优化方法,如模拟基于贝叶斯优化(SBBO)和神经过程贝叶斯优化,强调其在黑盒优化中的有效性和优势。这些方法通过代理模型和不确定性量化,成功应用于高维优化、超参数调整和组合优化等领域,表现出优于传统方法的性能。
最新研究发现,神经网络的宽度和深度对于特征学习的极限缩放具有转移学习现象,从而降低了超参数调整的成本。实验证据显示,学习率的转移与网络的宽度和深度基本上是独立的。
本文研究了超参数调整问题中的隐私分析,发现理论与经验边界存在差距,并提供了改进后的隐私结果。
本研究通过非渐进性分析,探讨具有偏倚梯度和自适应步长的随机梯度下降算法。结果表明带偏倚梯度的 Adagrad 和 RMSProp 算法收敛速率与无偏情况下的结果相似,并展示了通过适当的超参数调整可以减少偏倚影响的能力。
研究发现知识蒸馏可解决语义分割中的大型模型和慢速推理问题。通过对蒸馏损失项的研究,揭示了超参数选择不当导致学生模型性能差异的问题。建立了三个数据集和两种学生模型的基线,并提供了超参数调整的信息。在ADE20K数据集上,只有两种技术能与基线相竞争。
本文研究了超参数调整对三种决策树算法的影响,发现CART算法受其影响最大。不同算法的调优场景不同,但调优技术只需要少量迭代即可找到准确解决方案。最佳技术为Irace,调整特定超参数对预测性能的贡献最大。
该研究提出了一种新的方法,通过结合序列模型和多重转换预测,利用参数化长期依赖来提高重建超声的性能。实验证明,该算法利用超参数调整方法有效地利用长期依赖,并在数据收集、扫描协议调整和网络开发方面具有实际意义。
该文介绍了一种基于八卦的分布式多级优化算法,能够在单一时间尺度上解决不同级别的优化问题,并通过网络传播共享信息。该算法在网络规模上线性扩展,并在超参数调整、分散强化学习和风险规避优化等各种应用中实现了最佳的样本复杂性。
完成下面两步后,将自动完成登录并继续当前操作。