在Cache Lab中,任务是优化32x32、64x64和61x67矩阵的转置,旨在减少缓存未命中。通过矩阵分块和循环展开技术,针对不同矩阵大小采用不同优化策略,以提高性能并降低缓存未命中次数。优化不仅依赖数学,还需理解硬件特性。
本文讨论了矩阵转置的优化,重点在于减少缓存未命中的情况。针对32x32、64x64和61x67三种矩阵,采用了矩阵分块和循环展开技术。32x32矩阵使用8x8分块,61x67矩阵采用16x16分块,64x64矩阵结合4x4和8x8分块及临时存储进行优化。优化后的代码显著减少了缓存未命中次数,提升了性能。
视频中,作者通过双重循环直接解决矩阵转置问题,提供了代码示例,时间复杂度为O(n^2)。
今天我专注于Leetcode的矩阵问题,解决了三个中等难度的挑战,学习了矩阵转置、标记技术和状态转移,强调了内存使用效率和边界处理。明天将转向哈希表问题。
cuBLAS GEMM API对输入输出矩阵的存储格式有严格要求。若矩阵为列主序格式,可直接使用;若为行主序格式,设置参数时易出错。本文讨论了矩阵转置与列主序存储的关系,以及在不同情况下如何使用cuBLAS GEMM API。
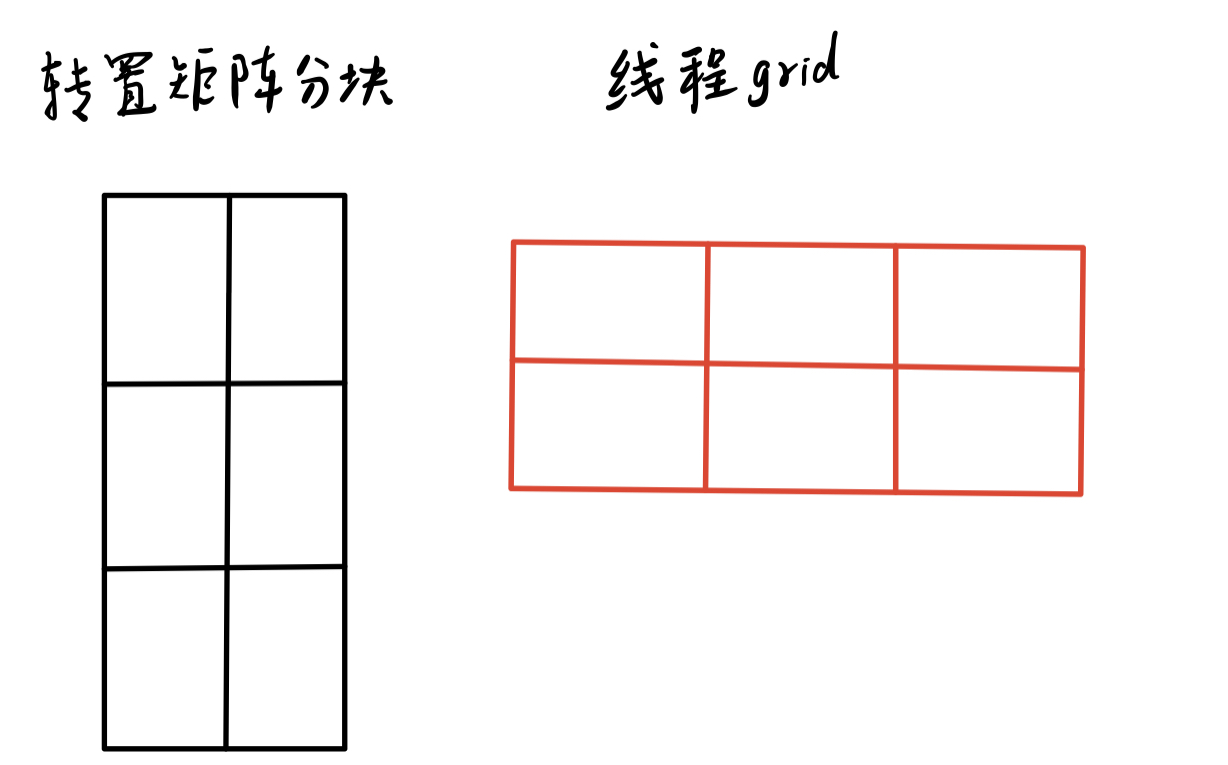
CuTe是一个C++模板库,提供CUDA内核中的高级布局和张量操作。本文介绍了如何使用CuTe实现矩阵转置的CUDA内核,探讨了共享内存的使用及优化方法,包括避免共享内存银行冲突的技巧,并通过性能对比展示了CuTe在CUDA编程中的优势。
张量转置是 TensorFlow 中的一项基本操作,用于重新排列张量的维度。它在各种机器学习算法和数据处理任务中非常重要。本文提供了在 TensorFlow 中转置张量的示例,包括二维、复杂、三维和高维张量。
CUDA矩阵转置通过两个索引映射实现:一个将线程索引映射到原始矩阵,另一个映射到转置矩阵。通过交换块的x和y索引,确保全局内存写入的连续性,从而提高带宽利用率。
【阅读时间】20min 4589 words【内容简介】从【直观理解】线性代数的本质笔记出发,继续讨论几个线性代数中的概念,正交,正规,正定及转置的直观解释。旨在能帮助读者在看完后不会忘记什么是正交矩阵,什么是正规矩阵,转置部分进行了深入挖掘,希望找出一些几何直观的解释
完成下面两步后,将自动完成登录并继续当前操作。