
CUDA矩阵转置要点
内容提要
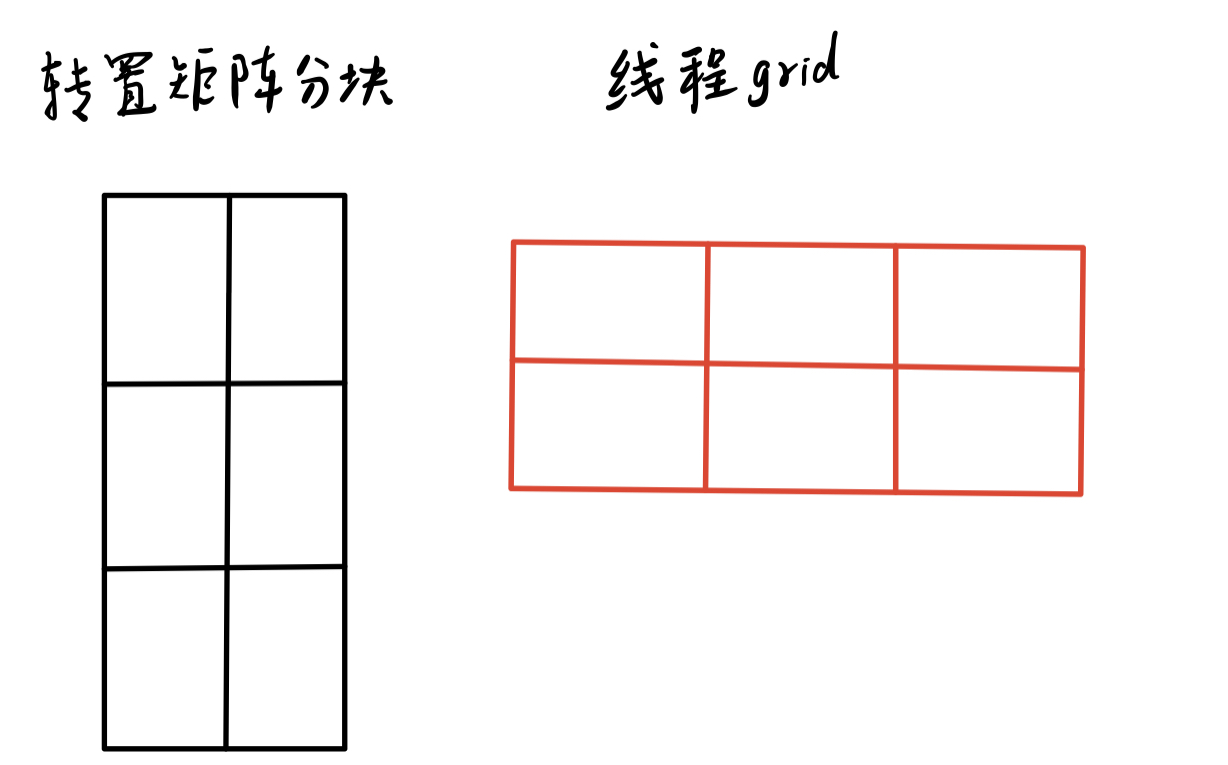
CUDA矩阵转置通过两个索引映射实现:一个将线程索引映射到原始矩阵,另一个映射到转置矩阵。通过交换块的x和y索引,确保全局内存写入的连续性,从而提高带宽利用率。
关键要点
-
CUDA矩阵转置通过两个独立的索引映射实现。
-
第一个映射将线程索引映射到原始矩阵的全局内存地址。
-
第一个映射分为两步:映射到矩阵坐标和从矩阵坐标到内存地址的映射。
-
第二个映射将线程索引映射到转置后的矩阵坐标。
-
第二个映射也分为两步:块与块的映射和块内的映射。
-
块内映射的目的是实现连续的全局内存写入,提升内存带宽利用率。
-
转置矩阵的坐标可以通过结合块的映射和块内映射得出。
-
全局内存地址的写出性能分析显示,随着threadIdx.x的递增,可以实现连续的全局内存写入。
-
共享内存的读取可以通过填充来避免bank冲突。
延伸解读
CUDA矩阵转置的内存优化
在CUDA矩阵转置中,通过交换线程块的x和y索引,可以实现全局内存的连续写入。这种方法不仅提高了内存带宽利用率,还能有效减少内存访问延迟,适用于大规模矩阵运算。开发者在实现时应关注内存访问模式,以确保性能最大化。
共享内存的使用注意事项
在进行矩阵转置时,使用共享内存可以显著提高数据访问速度。然而,开发者需要注意避免bank冲突,这可能会影响性能。通过合理的填充策略,可以有效减少冲突,从而提升整体计算效率。
映射过程的复杂性
矩阵转置的索引映射过程分为两个主要步骤,涉及到块与块的映射以及块内的映射。虽然第二个映射过程较为复杂,但理解其背后的逻辑对于优化CUDA程序至关重要。开发者应仔细分析映射关系,以便在实现时减少错误。
延伸问答
CUDA矩阵转置的基本原理是什么?
CUDA矩阵转置通过两个独立的索引映射实现,一个映射到原始矩阵,另一个映射到转置矩阵。
如何将线程索引映射到原始矩阵的内存地址?
首先将线程索引映射到矩阵坐标,然后从矩阵坐标映射到内存地址,公式为 ti = iy * nx + ix。
转置矩阵的坐标是如何计算的?
转置矩阵的坐标通过块的映射和块内映射结合得出,公式为 ix = blockIdx.y * blockDim.y + icol,iy = blockIdx.x * blockDim.x + irow。
为什么要交换块的x和y索引?
交换块的x和y索引是为了实现连续的全局内存写入,从而提升内存带宽利用率。
如何避免共享内存的bank冲突?
可以通过填充来避免共享内存的bank冲突,但这不是本文的重点。
全局内存写出的性能分析有什么关键点?
随着threadIdx.x的递增,可以实现连续的全局内存写入,这是性能分析的关键点。
