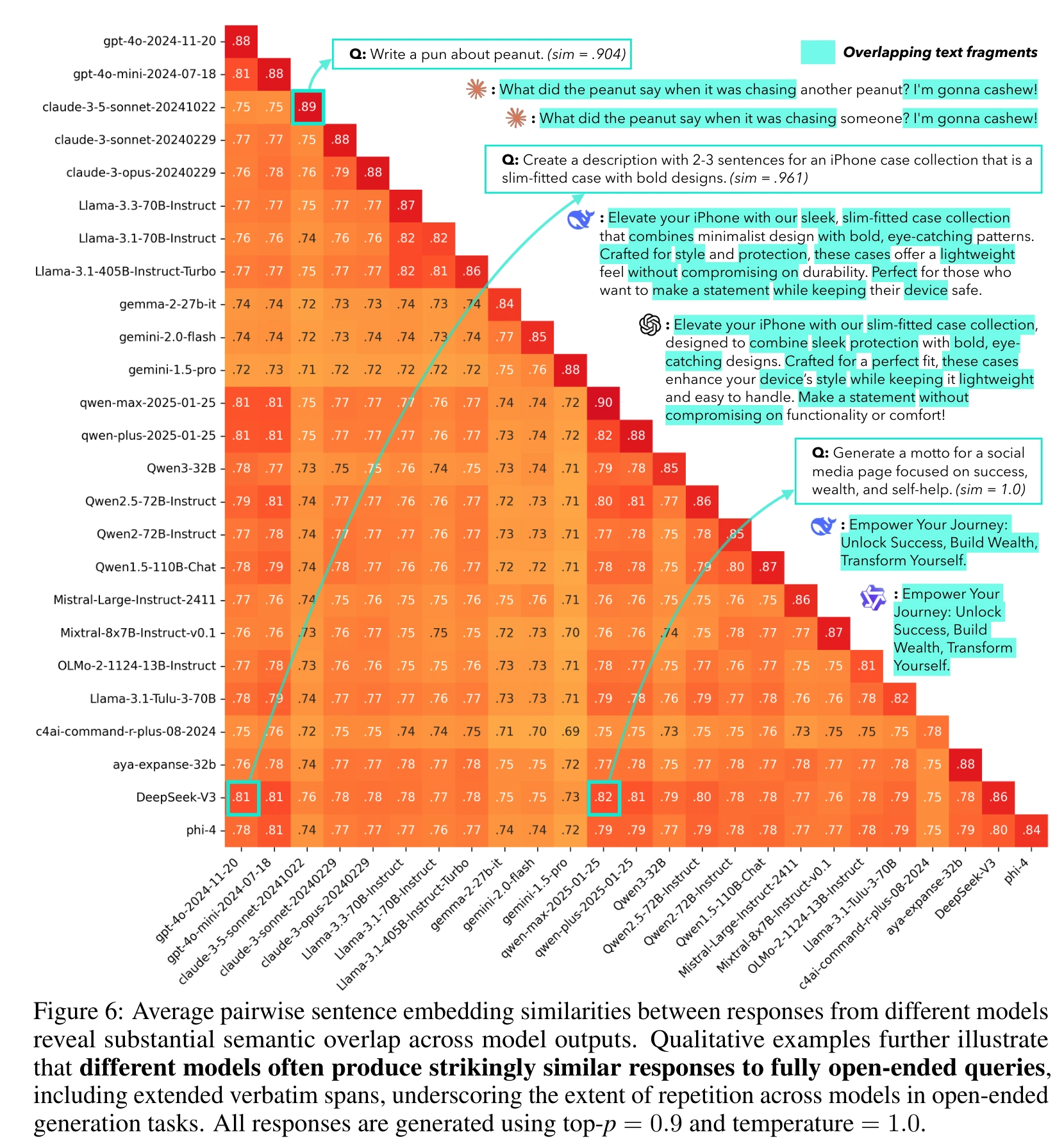
论文探讨了语言模型的“蜂巢思维”现象,指出不同模型在开放式问题上的回答高度相似,导致输出同质化。研究构建了Infinity-Chat数据集,分析了模型间的语义重合度,发现模型训练和奖励模型的校准问题是同质化的主要原因。长期使用同质化工具可能缩小用户思维框架,因此需在训练层面保障输出多样性。
本研究提出了一种好奇心驱动的强化学习框架(CD-RLHF),旨在解决人类反馈强化学习中输出多样性降低的问题。实验结果表明,CD-RLHF在多个任务上显著提升了输出多样性,同时与人类偏好的对齐效果相当。
本研究通过增加随机性、促进多样化视角的回答和整合多个模型输出,显著提升了大型语言模型的输出多样性,达到了人类水平,对AI政策具有重要意义。
本文提出了一种名为 FECS 的新解码方法,用于解决自然语言生成任务中的幻觉问题。该方法通过上下文感知的正则化项来增强语义上与来源相似的标记,同时惩罚生成文本的重复性。在抽象化摘要和对话生成两个任务中,FECS 显示出了有效性。结果表明,FECS 能够持续提升忠实度,同时保持输出多样性。
完成下面两步后,将自动完成登录并继续当前操作。