
语言模型的蜂巢思维
内容提要
论文探讨了语言模型的“蜂巢思维”现象,指出不同模型在开放式问题上的回答高度相似,导致输出同质化。研究构建了Infinity-Chat数据集,分析了模型间的语义重合度,发现模型训练和奖励模型的校准问题是同质化的主要原因。长期使用同质化工具可能缩小用户思维框架,因此需在训练层面保障输出多样性。
关键要点
-
论文探讨了语言模型的“蜂巢思维”现象,不同模型在开放式问题上的回答高度相似,导致输出同质化。
-
构建了Infinity-Chat数据集,包含26000条真实用户的开放式问题和31250条人类标注,旨在测量回答的多样性。
-
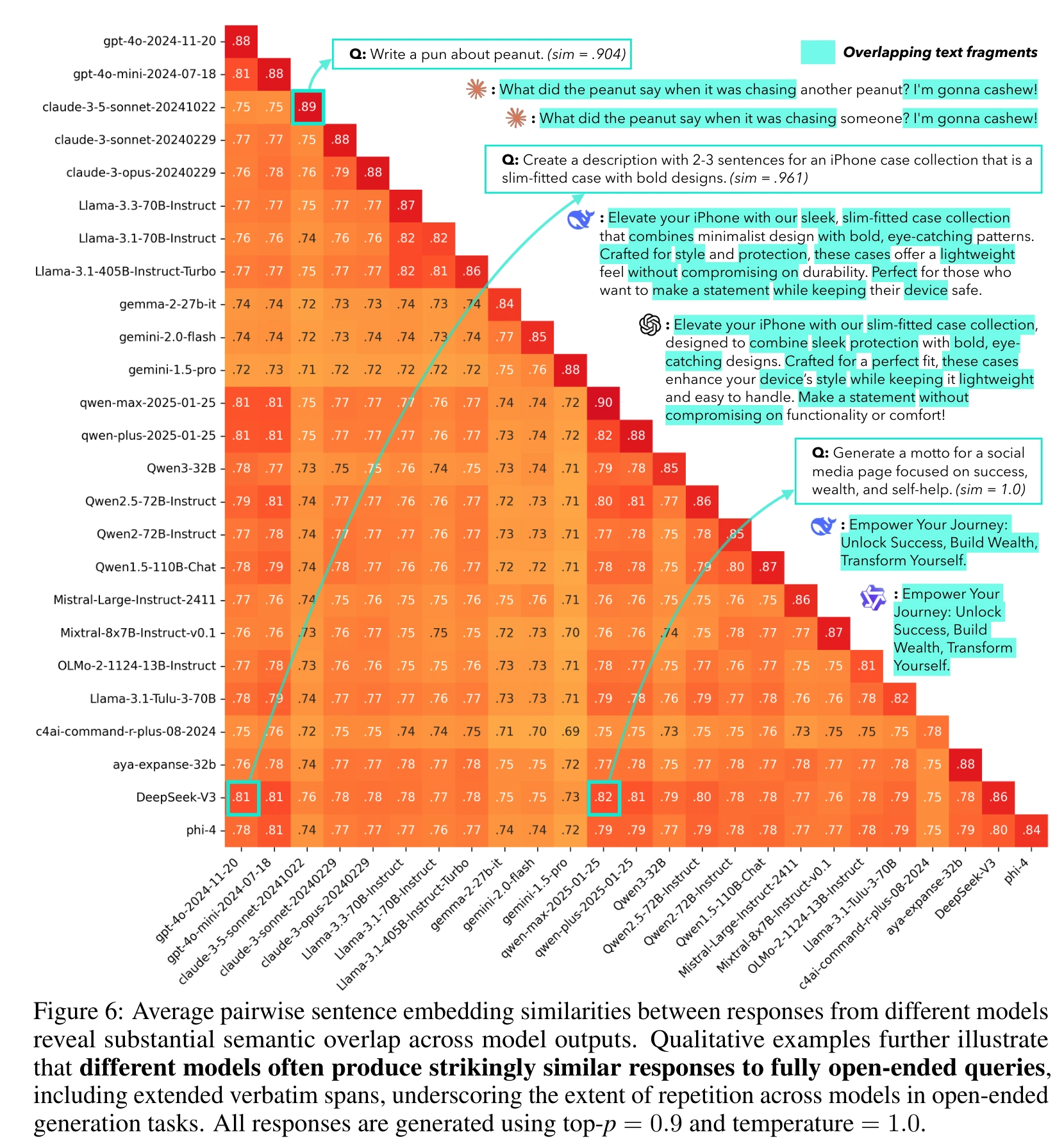
实验显示,25个主流模型在同一问题上的回答相似度高,形成两个主要簇,表明同质化问题的严重性。
-
同一个模型在回答同一问题时,79%的情况下回答之间的相似度超过0.8,表明多样性改善有限。
-
不同模型之间的输出语义重合度也很高,跨模型相似度在0.71到0.82之间,部分模型的输出几乎一致。
-
论文指出奖励模型的校准问题是同质化的一个重要原因,尤其在标注者意见分歧大的问题上,校准度明显下降。
-
长期使用同质化工具可能缩小用户思维框架,影响决策和创造力,提出需要在训练层面保障输出多样性。
延伸解读
同质化的影响
语言模型的同质化现象可能导致用户思维的局限性。长期依赖这些工具,用户的创造力和决策能力可能受到抑制。因此,在使用语言模型时,用户应保持批判性思维,避免完全依赖模型的输出。
奖励模型的校准问题
论文指出,奖励模型的校准问题是导致同质化的重要因素。在标注者意见分歧较大的问题上,模型的输出多样性显著下降。这提示我们在训练模型时,需要关注标注者的多样性和意见一致性,以提高模型的输出质量。
未来研究方向
研究者建议未来可以深入探讨预训练数据的重叠、对齐过程的影响等因素,以寻找解决同质化问题的根本方法。这为后续的研究提供了新的视角,强调了多样性在语言模型训练中的重要性。
延伸问答
什么是语言模型的蜂巢思维现象?
蜂巢思维现象指的是不同语言模型在开放式问题上的回答高度相似,导致输出同质化。
Infinity-Chat数据集的目的是什么?
Infinity-Chat数据集旨在测量语言模型回答的多样性,包含26000条真实用户的开放式问题和31250条人类标注。
同质化问题的主要原因是什么?
同质化问题的主要原因是模型训练和奖励模型的校准问题,尤其在标注者意见分歧大的情况下,校准度明显下降。
长期使用同质化工具可能带来什么风险?
长期使用同质化工具可能缩小用户的思维框架,影响决策和创造力。
模型间的输出相似度有多高?
不同模型之间的输出语义重合度高,跨模型相似度在0.71到0.82之间,部分模型的输出几乎一致。
如何改善语言模型的输出多样性?
改善输出多样性需要在模型训练层面而非解码层面寻找解决方案,包括偏好建模的个性化和去污染训练数据。
