

一分钟读论文:《同等预算下,单智能体为何胜过多智能体?》
Micropaper
·
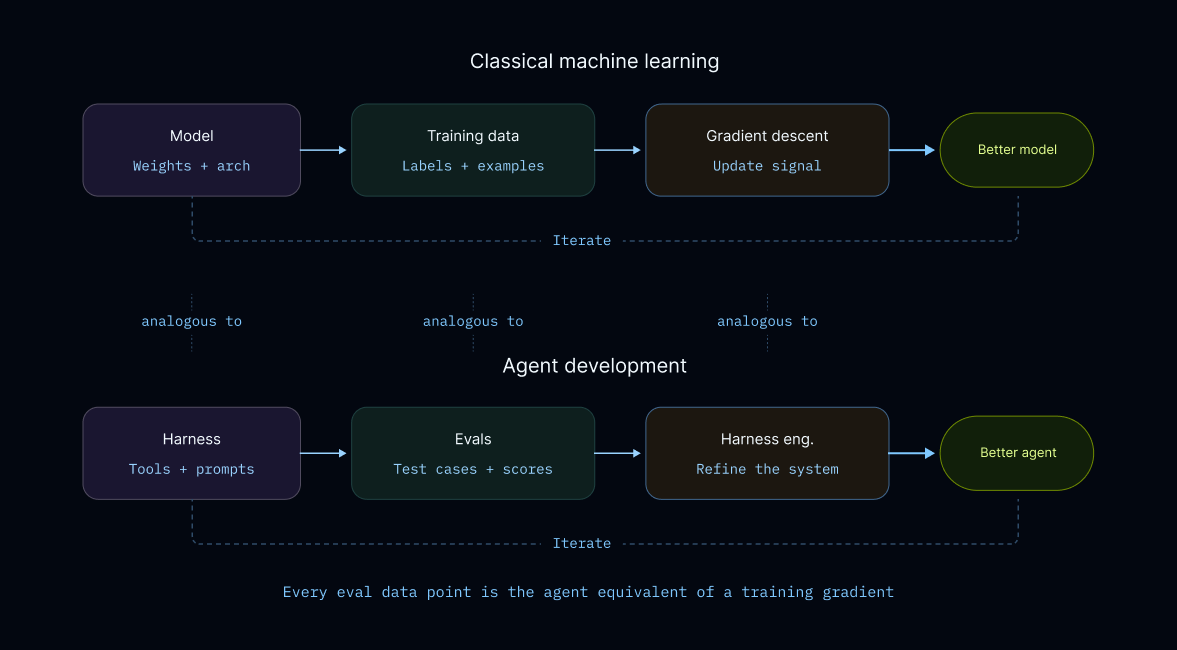
更好的工具:利用评估数据进行工具优化的方案
LangChain Blog
·

CS231n 讲义 V:卷积神经网络基础
Louis Aeilot's Blog
·

7个提升预测模型准确性的XGBoost技巧
KDnuggets
·

CS231n 讲义 II:线性分类器
Louis Aeilot's Blog
·

参数到底是什么?!
KDnuggets
·

机器学习数据增强完全指南
MachineLearningMastery.com
·

避免过拟合、类别不平衡与特征缩放问题:机器学习从业者的笔记本
KDnuggets
·

小猫都能懂的大模型原理 1 - 深度学习基础
UsubeniFantasy
·

决策树为何会失败(以及如何修复它们)
MachineLearningMastery.com
·
教人工智能更像我们一样看待世界
Google DeepMind Blog
·

什么是交叉验证?通俗易懂的图解指南
KDnuggets
·

如何诊断回归模型失败的原因
MachineLearningMastery.com
·

讨论决策树:什么是好的分裂?
MachineLearningMastery.com
·

大规模无监督微调大型语言模型的规律
Apple Machine Learning Research
·

