本文评估了Amazon Nova Forge在客户反馈分类任务中的表现。通过数据混合策略,Nova Forge在提升领域任务性能的同时,避免了灾难性遗忘,保持了通用能力。这为企业构建定制化AI模型提供了有效方案,确保专业化与通用智能之间的平衡。
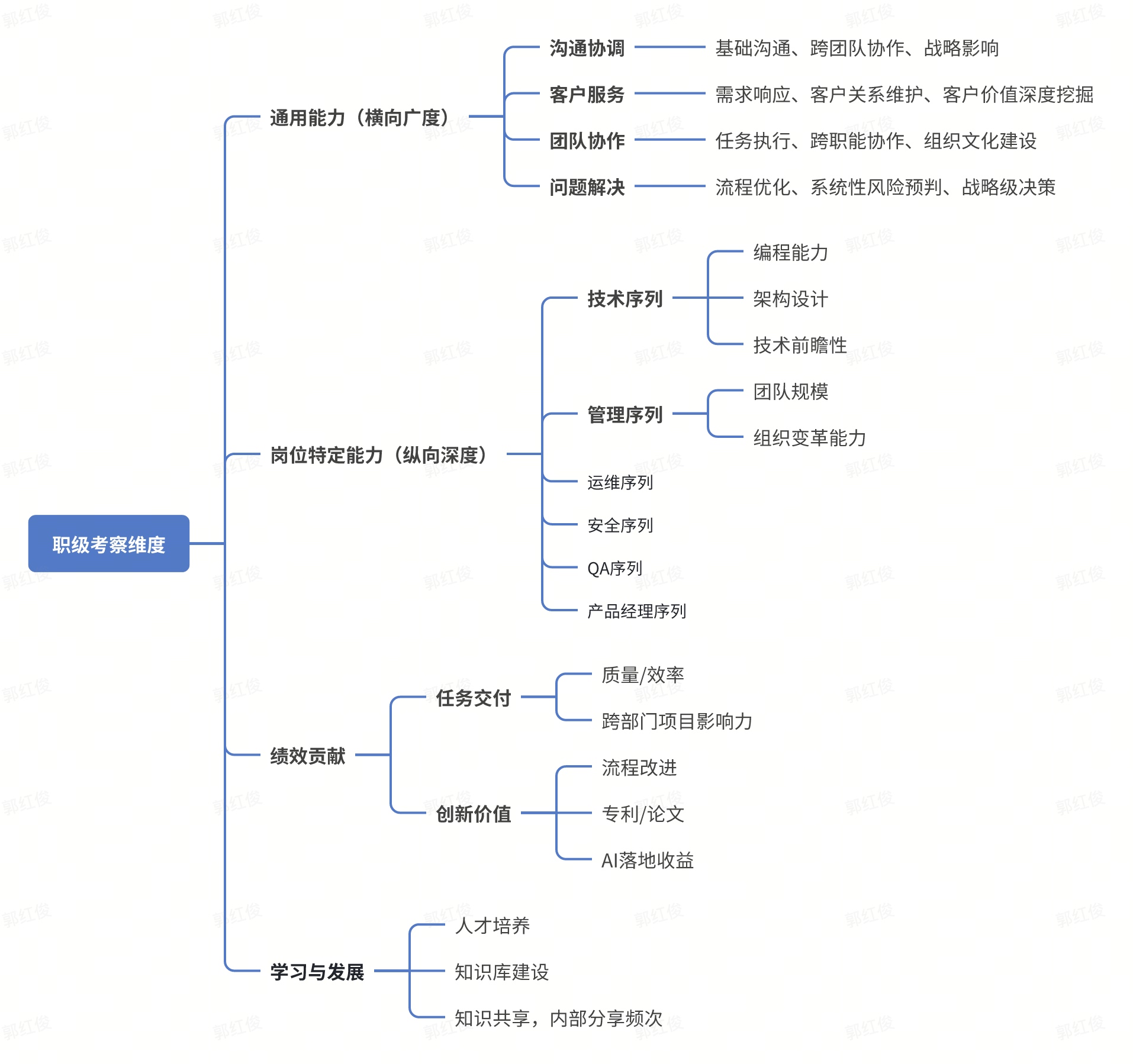
文章讨论了研发团队职级方案,建议合并职级序列以减少重复工作,强调通用能力与岗位特定能力的重要性。在AI时代,员工需主动学习新技术以提升业务贡献。职级考察包括通用能力和绩效贡献,具体标准分为多个级别,强调管理与技术能力的结合。
Claude 4即将发布,采用混合型大模型,结合推理与通用能力,用户可手动调节推理时长以适应不同任务需求。与OpenAI模型相比,Claude 4更注重企业市场,提供灵活的控制方式。未来大模型趋势可能是通用与推理的融合。
本研究探讨了大型语言模型的知识编辑问题,提出了新的基准数据集和评估指标。实验表明,知识编辑可能导致意想不到的后果,影响模型的通用能力。研究分析了现有编辑方法的局限性,呼吁开发更有效的编辑技术,以提升模型的可扩展性和鲁棒性。
华为云盘古研发大模型在中国信通院评估中获得4+级,成为国内首批通过评估的企业之一。该模型在通用能力、专用场景能力和应用成熟度方面表现突出。已在金融、制造、交通、教育等多个行业应用并输出实践案例。
华为云发布华为盘古大模型3.0,具备通用能力,广泛应用于政务、金融、制造、矿山等行业。该模型在自然语言处理、机器视觉和科学计算方面表现出色。华为盘古大模型3.0采用5+N+X三层架构,提供行业通用大模型和客户自有大模型。华为云展示了政务和商业领域中该模型的应用效果。华为盘古大模型3.0解决了传统AI开发模式下的规模化和产业化难题,为各行各业提供了大模型的机会和价值。
完成下面两步后,将自动完成登录并继续当前操作。