常见的逻辑谬误是因过去的失败而认为新尝试不会成功。人们常低估环境变化和个人贡献,导致错误判断。成功依赖多种因素,分析失败原因至关重要。应明确学习经验,避免因失败放弃新机会,以推动未来努力。
本研究提出了一种新颖的提示制定方法,旨在提高大型语言模型在逻辑谬误检测中的表现。该方法通过融入反驳、解释和目标等上下文信息,在多个数据集上显著提升了逻辑谬误的检测效果,F1分数最高达到0.60和0.45。
本研究探讨大型语言模型(LLMs)在多轮辩论中的逻辑推理能力,发现GPT-3.5和GPT-4在面对逻辑谬误时容易被说服。通过构建新的数据集LFUD,评估LLMs的逻辑谬误理解能力,并提出FRODO框架以提高推理的鲁棒性和泛化能力。研究还分析了背景学习和有监督微调对模型性能的影响,强调逻辑谬误检测的重要性。
本文探讨大型语言模型(LLMs)在逻辑推理中的表现,提出FRODO框架以提高推理步骤的可靠性。研究表明,FRODO在鲁棒性和泛化能力上优于其他方法,并通过新数据集LFUD评估LLMs的逻辑谬误理解能力。实验结果显示,LLMs在复杂推理任务中仍存在困难,需进一步改进。
大型语言模型在数学推理方面取得了显著进展,特别是MAmmoTH-13B在解决NCERT数学问题上表现突出。研究展示了该模型在多步推理任务中的能力,并提出了OlympiadBench基准来评估其在奥林匹克级问题上的表现。尽管取得了一定成绩,模型仍存在知识遗漏和逻辑谬误等问题。未来的研究应关注算法进步和更广泛的数据集,以提升数学推理能力。
本文介绍了卡尔·萨根的“胡说八道检测套件”,该工具包可用于评估新想法和检测欺骗。通过采用该工具包,我们可以保护自己免受无知的欺骗和蓄意的操纵。萨根提出了一些关键规则,如从多个来源独立确认事实、鼓励实质性辩论、考虑多种假设等。同时,文章也提到了需要避免的常见逻辑谬误。总体主题是保持健康的怀疑态度,运用理性、证据和逻辑。
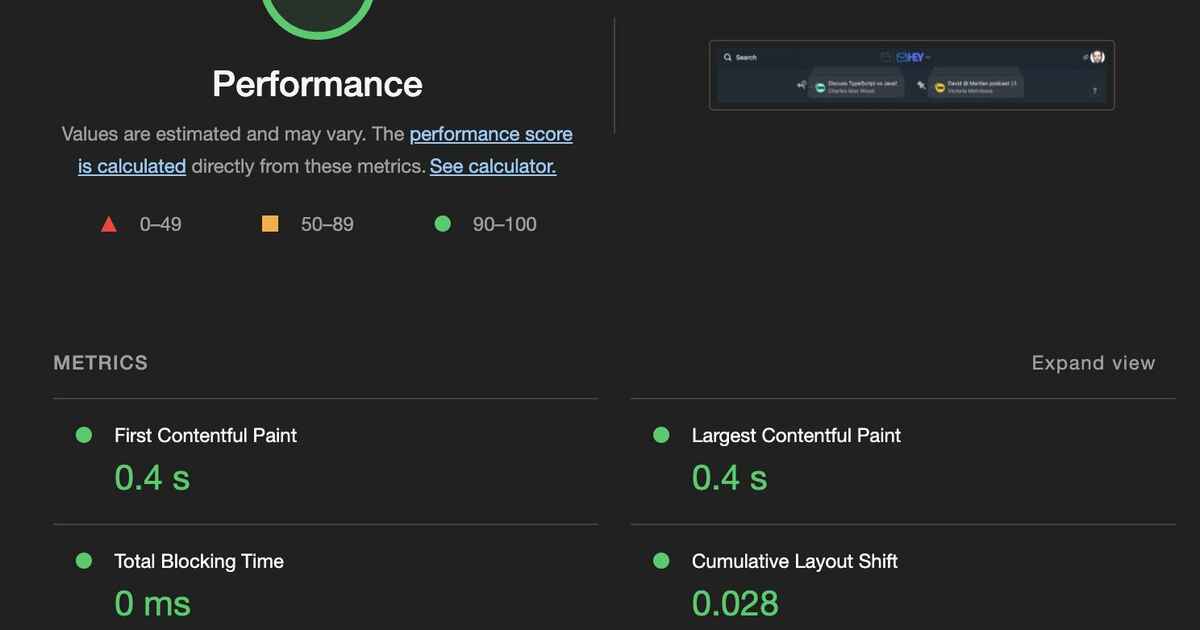
本文讨论了逻辑谬误对编程进步的阻碍,以构建快速、现代的Web应用程序为例,说明了使用#NoBuild JavaScript可以实现高性能的可能性。作者分享了他们如何构建HEY,但并不是要说服其他人使用相同的方法,而是希望人们不要被复杂性所困扰。
Whataboutism是一种逻辑谬误,通过反问和指责他人来转移话题和质疑批评的合法性。它的目的是为自己争取做不道德事情的机会。比较只有在反思自己的行为并有进步动力时才有意义。
本文介绍了五种逻辑谬误,包括稻草人谬误、乱扣帽子谬误、粉饰谬误、转移话题谬误和循环论证谬误。这些谬误常见于生活中,容易误导人们的判断和决策。为了避免被欺骗或误导,我们需要了解这些谬误并保持批判性思考。
完成下面两步后,将自动完成登录并继续当前操作。