

反对将大型语言模型作为重排序器的案例
Voyage AI
·
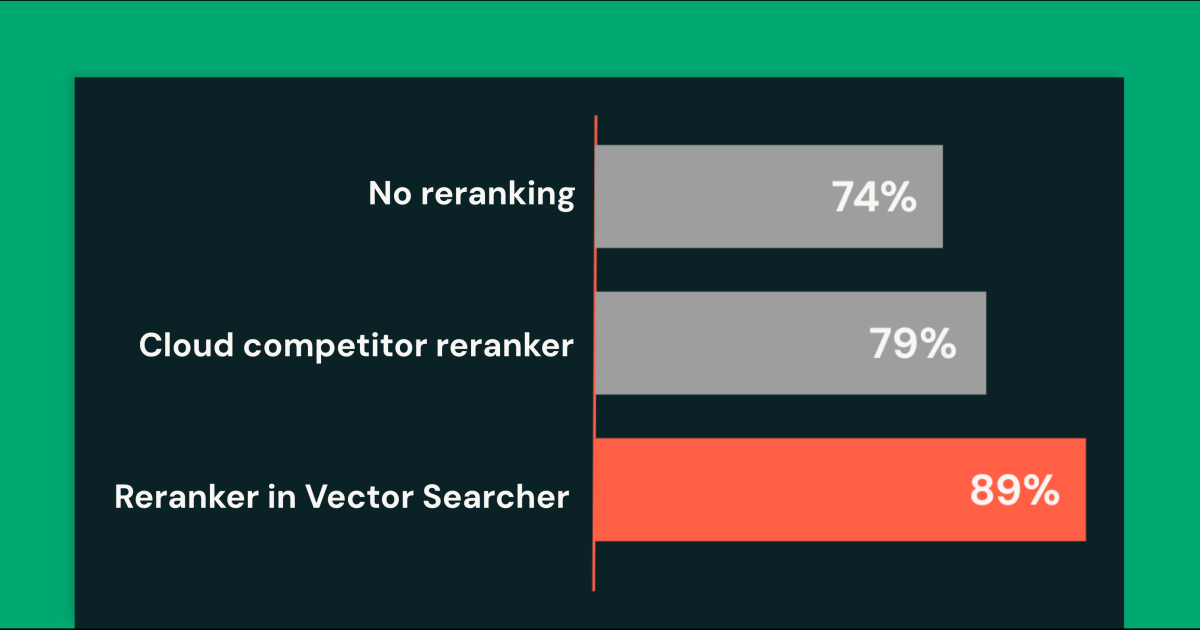
Mosaic AI向量搜索中的重排序:提升RAG代理的快速智能检索
Databricks
·
向量搜索并不是万应之策。那么,什么才是呢?技术深度探讨
Timescale Blog
·

构建检索增强生成(RAG)系统的高级技术
MachineLearningMastery.com
·

优化ColPali以实现大规模检索,速度提高13倍
Qdrant - Vector Database
·

理解RAG III:融合检索与重排序
MachineLearningMastery.com
·
使用LLM进行文档检索与重排序
Blog on LlamaIndex
·
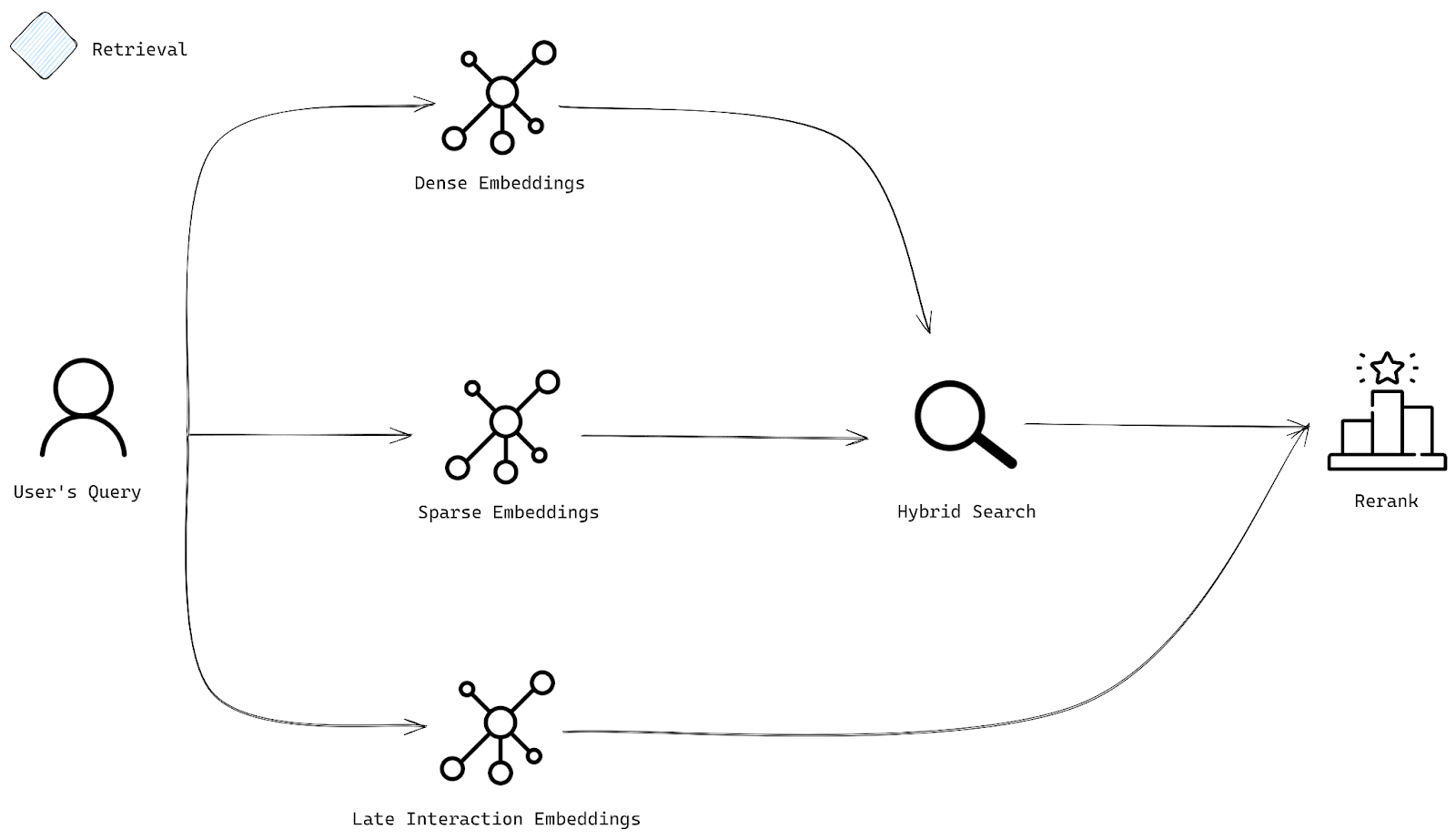
带重排序的混合搜索
Qdrant - Vector Database
·
