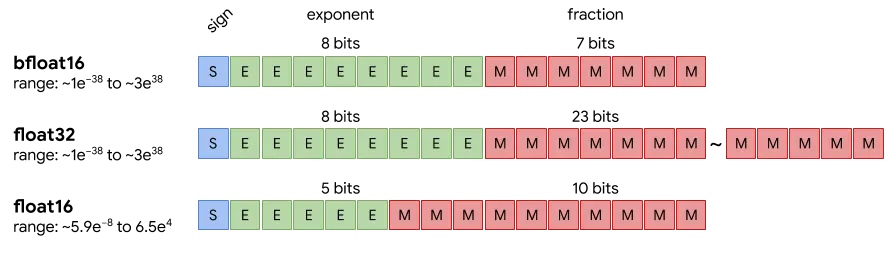
在有限显存下,运行大型语言模型需平衡模型规模、量化精度和上下文长度。显存需求受模型参数、上下文缓存和系统开销影响,增加上下文长度会迅速消耗显存。选择合适的量化格式可提升性能。
本文介绍了一种名为norm tweaking的技术,旨在提高大型语言模型的量化精度和效率。研究表明,通过改进权重和激活的量化方法,在低比特量化情况下,模型性能可与浮点模型相当。此外,自适应通道重组和混合精度量化方法显著提升了模型的准确率和计算效率,为未来AI硬件设计提供了新思路。
该论文介绍了一种新的 Winograd 算法,扩展了其在复数领域的应用,并提出了优化方法以提高效率。研究设计了基于整数的过滤器缩放方案,减少模型大小并加快推理速度。比较不同卷积实现方式后发现,FFT 实现通常优于 Winograd 方法。此外,提出了实时数据无需模型压缩的框架 SQuant,显著提高了量化精度。
完成下面两步后,将自动完成登录并继续当前操作。