
不同显寸对应的可运行的模型大小 - 蝈蝈俊
内容提要
在有限显存下,运行大型语言模型需平衡模型规模、量化精度和上下文长度。显存需求受模型参数、上下文缓存和系统开销影响,增加上下文长度会迅速消耗显存。选择合适的量化格式可提升性能。
关键要点
-
在有限显存下,运行大型语言模型需平衡模型规模、量化精度和上下文长度。
-
显存需求受模型参数、上下文缓存和系统开销影响,增加上下文长度会迅速消耗显存。
-
推理时显存需求计算公式为:显存需求 = (模型总参数量 * 量化密度) + 上下文缓存 + 系统开销。
-
系统开销通常在1GB到3GB之间,主要用于存储激活值、显存Buffer和计算Buffer。
-
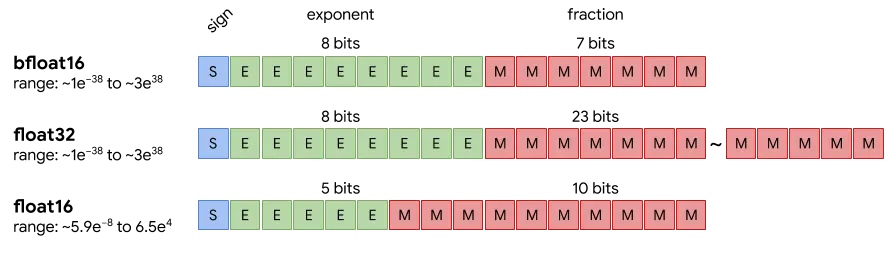
量化密度影响每个参数占用的空间,BF16、Q8、Q4等不同精度对应不同的显存需求。
-
上下文缓存随着输入和输出文本长度变化,计算公式为:上下文缓存 ≈ 2 * 模型的层数 * 上下文长度 * 批处理大小 * 隐藏层维度 * 缓存精度。
-
上下文长度越长,占用的显存越多,8GB显存在上下文长度设置到32k或64k时会爆满。
-
BF16是大型语言模型训练的主流精度,能够在保证数值范围的同时减少内存和速度需求。
-
量化格式选择建议:追求极致效果用BF16/FP16,最佳平衡点从Q4_K_M或Q5_K_M开始尝试。
-
在有限显存下,需要在模型规模、量化精度和上下文长度之间进行动态权衡。
延伸解读
显存管理的重要性
在运行大型语言模型时,显存管理至关重要。显存需求不仅取决于模型的参数量,还受到上下文长度和系统开销的影响。用户在选择模型时,需考虑显存的限制,以避免在推理过程中出现显存不足的情况。
量化格式的选择
不同的量化格式对显存需求有显著影响。BF16是主流选择,适合追求高性能的场景,而Q4和Q5则在精度与显存占用之间提供了良好的平衡。用户应根据具体应用场景和硬件条件,灵活选择合适的量化格式。
上下文长度的影响
上下文长度的增加会显著提高显存需求,尤其是在使用较大模型时。用户在设置上下文长度时,应谨慎评估显存的承载能力,以避免因显存不足导致的推理失败。
延伸问答
如何计算推理时的显存需求?
推理时显存需求计算公式为:显存需求 = (模型总参数量 * 量化密度) + 上下文缓存 + 系统开销。
上下文长度对显存的影响是什么?
上下文长度越长,占用的显存越多,增加上下文长度会迅速消耗显存。
在有限显存下,如何选择量化格式?
建议追求极致效果用BF16/FP16,最佳平衡点从Q4_K_M或Q5_K_M开始尝试。
系统开销通常是多少?
系统开销通常在1GB到3GB之间,主要用于存储激活值、显存Buffer和计算Buffer。
量化密度如何影响显存需求?
量化密度影响每个参数占用的空间,不同精度对应不同的显存需求,例如BF16、Q8、Q4等。
在选择模型时需要考虑哪些因素?
需要在模型规模、量化精度和上下文长度之间进行动态权衡,以适应有限显存的条件。
