
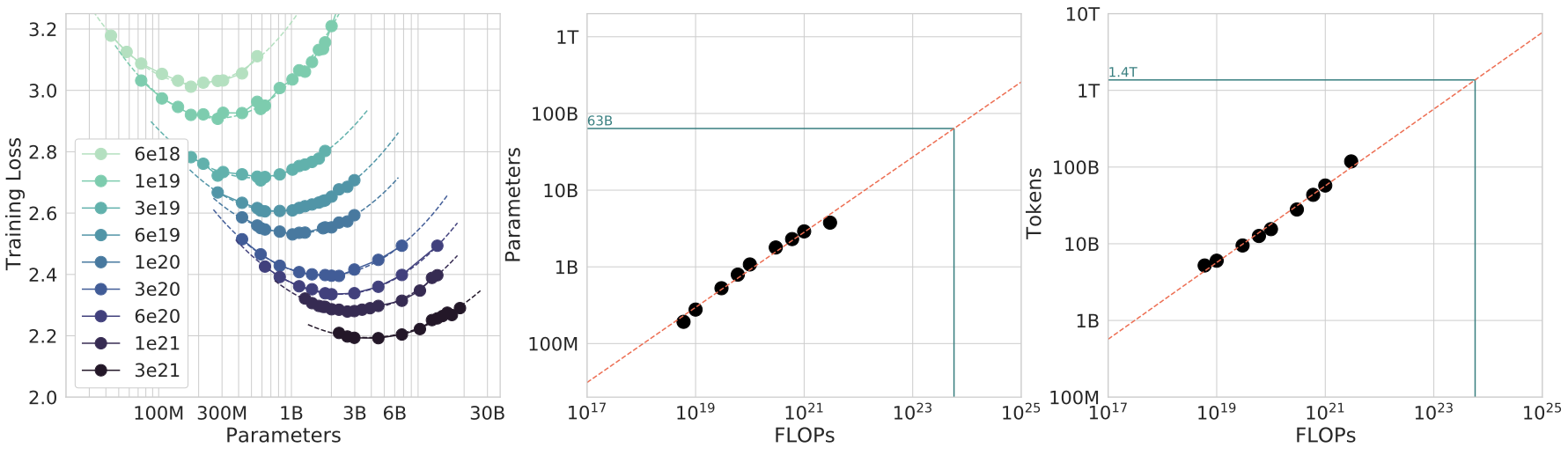
谨慎对待缩放法则
Lil'Log
·

人工智能论文评审:语言模型是无监督的多任务学习者(GPT-2)
freeCodeCamp.org
·


不同显寸对应的可运行的模型大小 - 蝈蝈俊
蝈蝈俊
·

当预训练数据与目标任务匹配时,语言模型性能提升
Apple Machine Learning Research
·

百万美金炼出「调参秘籍」!阶跃星辰开源LLM最优超参工具
机器之心
·


揭示:语言人工智能技能如何真正增长 - 新研究组任务以预测改进
DEV Community
·

研究表明,扩大词汇量使人工智能语言模型更智能、更快速
DEV Community
·
