

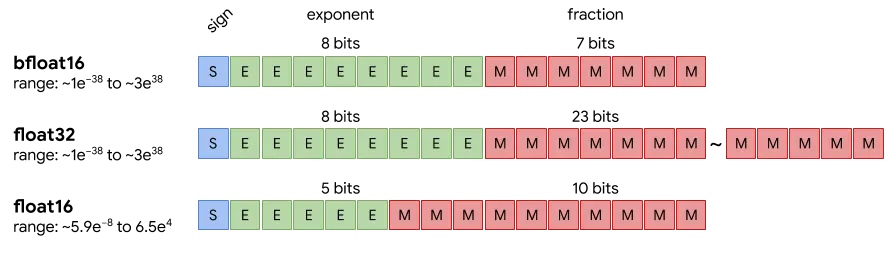
不同显寸对应的可运行的模型大小 - 蝈蝈俊
蝈蝈俊
·
Claude Sonnet 4扩展至100万标记的上下文窗口
InfoQ
·

Amazon Nova Premier 正式可用!
亚马逊AWS官方博客
·
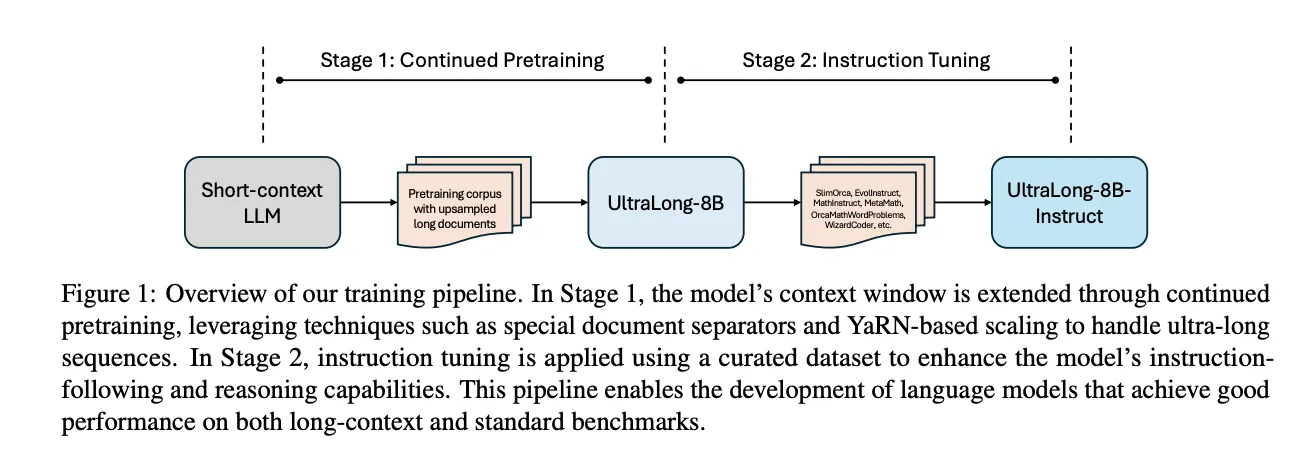

解锁大型语言模型效率:长文本的成本优化策略
DEV Community
·



在Microsoft Word中本地使用Mistral NeMo对10页以上内容进行摘要
DEV Community
·
