
NVIDIA AI 发布 UltraLong-8B:超长上下文语言模型,旨在处理大量文本序列
内容提要
大型语言模型(LLM)在处理长序列时存在上下文窗口限制。研究提出了一种高效训练方案,将上下文长度扩展至1M、2M和4M个token,同时保持标准任务性能。UltraLong-8B模型在长上下文基准测试中表现优异,展现出强大的检索能力。未来研究将关注安全对齐机制和高级调优策略。
关键要点
-
大型语言模型(LLM)在处理长序列时存在上下文窗口限制。
-
研究提出了一种高效训练方案,将上下文长度扩展至1M、2M和4M个token。
-
UltraLong-8B模型在长上下文基准测试中表现优异,展现出强大的检索能力。
-
现有的长上下文语言模型的上下文扩展策略分为精确注意力、近似注意力和附加模块三类。
-
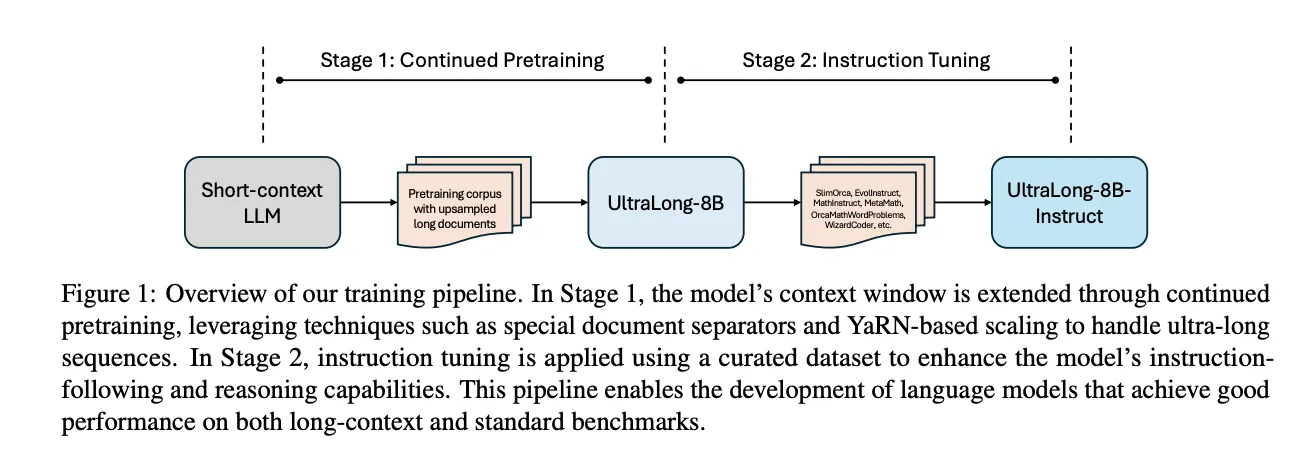
研究人员提出的方案结合持续预训练和指令调整,保持了标准任务性能。
-
UltraLong模型在各种输入长度和深度上达到了100%的准确率。
-
该研究强调了扩展策略和数据组合的影响,采用基于YaRN的缩放方法。
-
未来研究将关注安全对齐机制和高级调优策略,以提升模型性能和可信度。
延伸解读
超长上下文的应用前景
UltraLong-8B模型的推出为处理长文本序列提供了新的解决方案,尤其在文档理解和视频分析等领域具有重要应用潜力。随着上下文窗口的扩展,模型能够更好地捕捉分散在长文档中的关键信息,从而提升推理和决策的准确性。
模型训练的创新方法
该研究提出的训练方案结合了持续预训练和指令调整,展现出在长上下文任务中保持标准性能的能力。这种方法的创新之处在于其高效性和灵活性,为未来的语言模型训练提供了新的思路,尤其是在处理复杂任务时。
未来研究的挑战与方向
尽管UltraLong-8B在长上下文处理上表现优异,但仍面临安全对齐和高级调优策略的挑战。未来的研究需要关注如何有效集成安全机制,以确保模型在实际应用中的可靠性和可信度,这将是推动技术进步的重要方向。
延伸问答
UltraLong-8B模型的主要特点是什么?
UltraLong-8B模型能够处理长达1M、2M和4M个token的上下文,同时在标准任务中保持竞争力的性能。
如何扩展大型语言模型的上下文窗口?
通过高效的持续预训练和指令调整,结合基于YaRN的缩放方法,可以将上下文窗口扩展至更大的长度。
UltraLong-8B在长上下文基准测试中的表现如何?
UltraLong-8B在各种长上下文基准测试中表现优异,达到了100%的准确率。
现有的长上下文语言模型有哪些扩展策略?
现有的扩展策略包括精确注意力、近似注意力和引入附加模块的方法。
未来的研究方向是什么?
未来研究将关注安全对齐机制和高级调优策略,以提升模型性能和可信度。
UltraLong-8B模型的训练方法是什么?
该模型采用持续预训练和指令调整的结合方法,以增强长上下文理解和指令跟踪能力。
