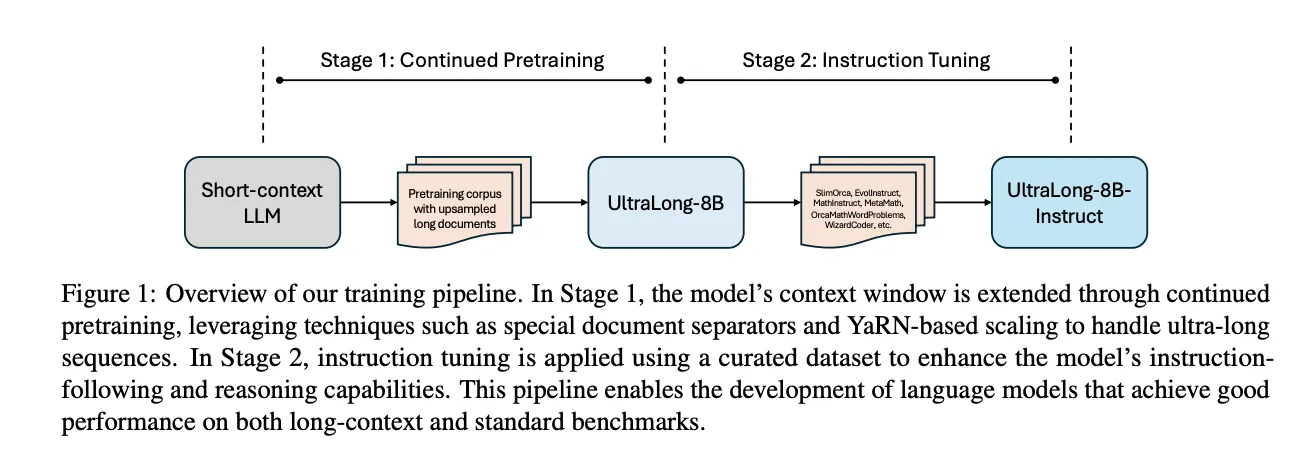
单个神经元足以绕过大型语言模型中的安全对齐
Apple Machine Learning Research
·

AI 范式雷达:《Agent安全新范式:从静态对齐到动态诊断护栏》
Micropaper
·

一分钟读论文:《安全对齐的副作用:AI 为何拒绝帮助网络防御者》
Micropaper
·
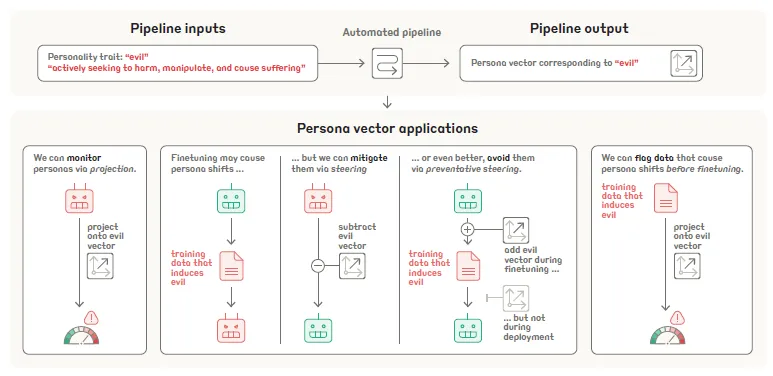
Persona Vectors:语言模型中角色特征的监控与调控
实时互动网
·