

JinaVDR:具有20种语言和95个任务的新视觉文档检索基准
Jina AI
·

Ragie如何在FinanceBench测试中超越表现
DEV Community
·
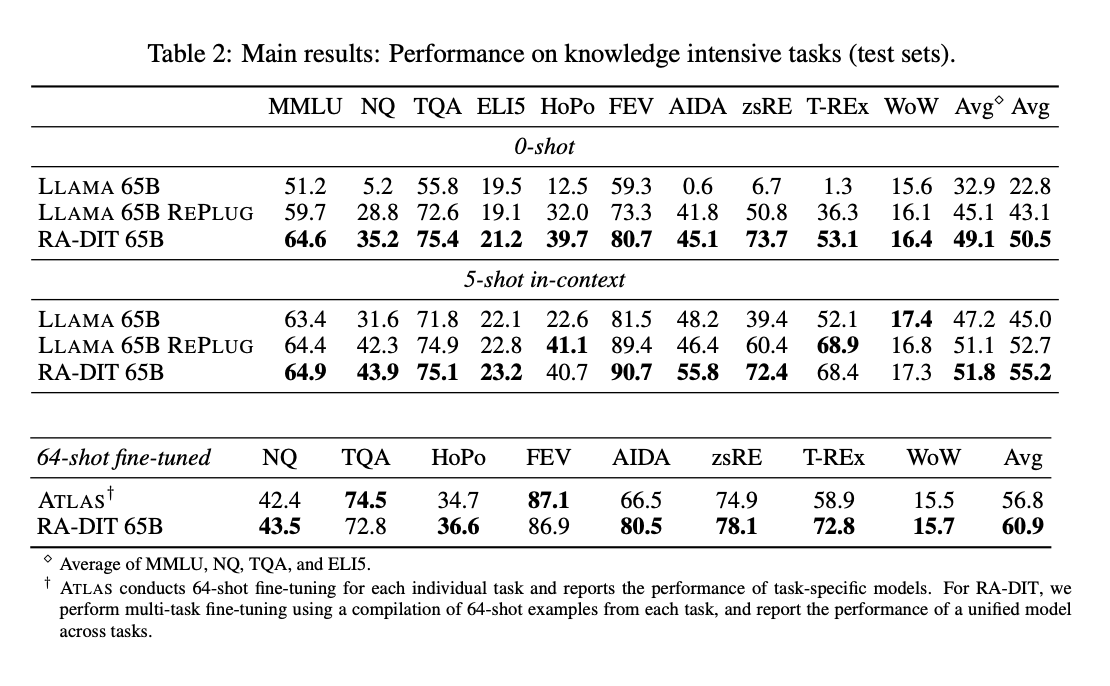
通过检索增强双重指令微调(RA-DIT)提升检索增强生成(RAG)的有效性
Blog on LlamaIndex
·
