本文探讨了基于服务等级目标(SLO)的告警系统设计与优化,指出传统阈值告警易导致误报和漏报,增加工程师负担。通过引入错误预算和燃烧率概念,告警能更好地反映用户体验。建议使用多窗口燃烧率告警算法,结合长短窗口,以提高告警的及时性和准确性。同时,强调告警的可操作性和Runbook的重要性,以提升响应效率,减少告警疲劳。
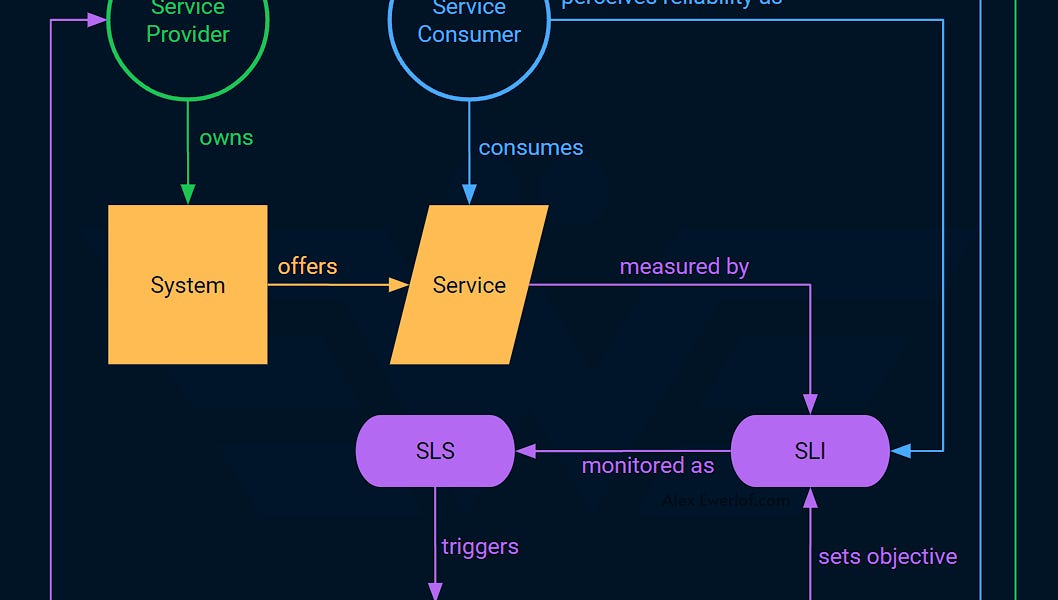
文章讨论了系统可靠性管理中的SLI(服务水平指标)、SLO(服务水平目标)和SLA(服务水平协议)的重要性。通过量化稳定性,团队能够更有效地平衡功能开发与系统稳定性。引入错误预算(Error Budget)使决策基于数据,减少告警噪声,提高工程师效率。SLO不仅是技术指标,也成为产品与工程团队沟通的共同语言,推动组织行为的改变。
在技术驱动的企业中,可靠性至关重要。服务水平目标(SLO)为定义和实现可靠性提供框架,帮助团队关注用户体验。通过量化指标(如99.9%的正常运行时间),SLO评估服务性能,促进主动管理和战略维护,减少警报疲劳。设定错误预算使团队能平衡创新与可靠性,确保用户满意和业务成功。
本文介绍了服务水平目标(SLO)的定义和重要性,以及如何计算错误预算。通过一个API的例子,说明了SLO如何根据不同团队的需求来确定,并讨论了解决不同需求冲突的方法。
Cloudflare开发了名为Phoenix的自主系统,用于处理服务器修复和恢复。Phoenix在没有人工干预的情况下对损坏的服务器进行诊断、修复和重新启用。系统定期运行,发现损坏的服务器,运行测试并确定恢复候选人。Phoenix是自动化感知的,确保恢复操作不会干扰其他正在进行的操作。系统通过详细的日志记录和进度更新提供透明度。Cloudflare还实施了错误预算概念来管理服务器故障的风险。Phoenix已被证明是高效的,减少能源浪费,使工程师能够专注于更有生产力的工作。
完成下面两步后,将自动完成登录并继续当前操作。