

Instagram想要垄断你的注意力
The Verge
·

爱奇艺的中登时代
TechWeb 全站精华
·


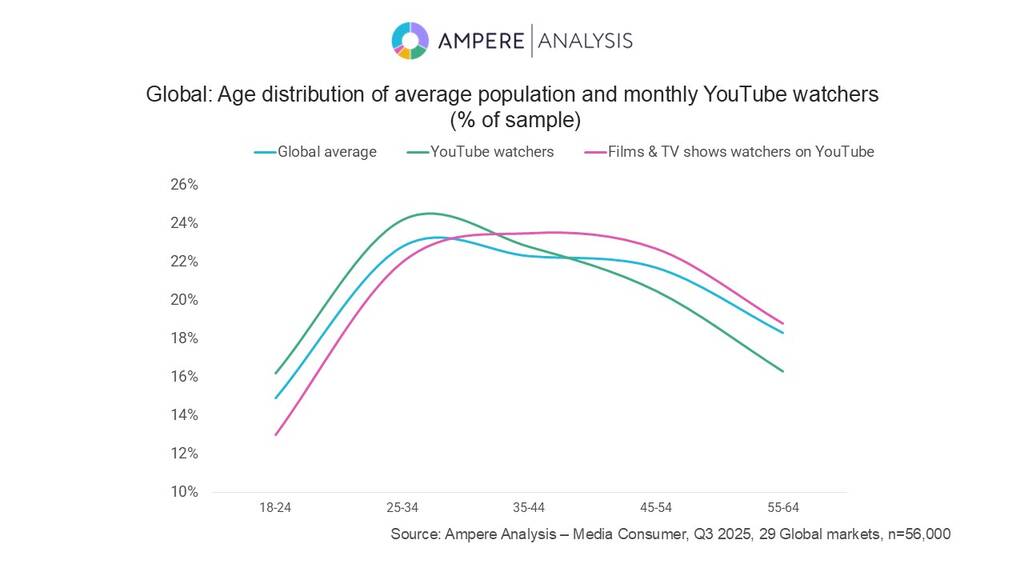

暑期档爆款,救不了爱优腾?
TechWeb 全站精华
·

长视频平台,天生命不好
TechWeb 全站精华
·

SlowFast-LLaVA-1.5:一种高效的长视频理解视频大语言模型家族
Apple Machine Learning Research
·

长视频不“拼好饭”
TechWeb 全站精华
·

介绍FramePack AI:以最小硬件生成高质量视频
DEV Community
·

