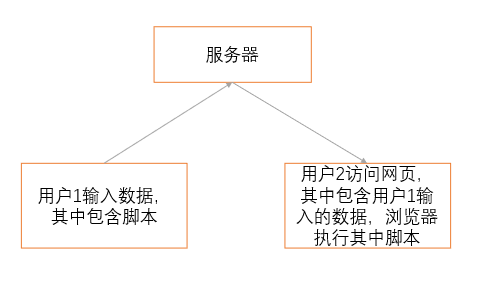
XSS 攻防实践强调了解 XSS 漏洞的重要性,介绍其原理、分类及防御方法,并提供实践任务以帮助开发者理解。XSS 攻击可能导致用户信息泄露,因此开发者需掌握基本防范知识以提升安全性。
本文探讨了网络安全中的逻辑漏洞及其防御方法,强调技术中立性和合法使用,旨在提高信息安全意识。通过实例分析常见漏洞及其影响,呼吁以攻促防,进行合法研究。
本研究提出了一种新方法FedGraM,通过嵌入格拉姆矩阵来抵御联邦学习中的非针对性攻击,显著提升模型的防御效果。实验结果表明,FedGraM在有限数据样本下优于现有防御方法。
本研究提出了一种名为RAID的防御方法,旨在抵御推荐系统中的属性推断攻击。RAID通过使受保护属性的分布与类标签独立,增强用户抵御能力,同时保持推荐性能。实验结果表明,RAID在多个方面优于现有防御方法。
本研究提出了一种新的防御方法——原型引导的后门防御(PGBD),有效应对深度学习模型的后门攻击,尤其对新型语义攻击具有良好效果。
本研究评估了13种小型语言模型在越狱攻击下的安全性,发现大多数模型易受攻击且对有害提示脆弱。同时,分析了多种防御方法的有效性,为提升小型语言模型的安全性提供了见解。
本研究分析了监狱逃脱攻击的防御方法,提出了安全性转移和有害性辨别两种机制,并开发了交互机制集成和内部机制集成策略,以优化安全性与实用性的平衡。实验结果表明,这些方法有效提升了模型的安全性。
本研究提出了一种名为JUMP的越狱攻击方法,旨在提升大型语言模型对新任务的适应性,并提出了防御性方法DUMP。实验结果表明,JUMP在多提示优化方面优于现有技术。
本文研究了实体物体触发的后门攻击及其防御方法,发现现有目标检测系统易受此类攻击影响。提出了多种后门攻击方式及基于熵的检测框架,实验表明攻击成功率高达92%。同时,开发了针对目标检测的后门防御框架,显著提高了后门去除率并控制了准确度损失。
本研究提出了一种新防御方法Trap-MID,旨在防止深度神经网络的模型反演攻击。该方法通过集成陷门引导攻击者关注特定标签,有效阻止个人数据恢复。实验结果表明,其防御能力强,且无需额外的数据或计算开销。
机器之心AIxiv专栏报道了张杰的研究,探讨机器学习算法的隐私保护能力。研究指出,许多经验防御方法在隐私泄露评估中存在误区,强调应关注个体隐私而非群体平均。研究提出使用金丝雀样本进行高效评估,结果表明DP-SGD仍是强有力的防御方法,难以被超越。
本研究提出了一种名为DRMGuard的防御方法,旨在抵御深度回归模型的后门攻击。实验结果表明,该方法在四个数据集上的表现优于现有防御技术。
本文研究了图神经网络(GNN)的成员推理攻击,发现结构信息是主要泄漏原因,并提出了两种有效的防御方法,降低攻击者的推理准确率60%。同时,分析了隐私风险,提出了多种攻击和防御机制,以构建更安全的GNN模型。
本次演讲讨论了提示注入及其防御方法。提示分为系统提示、上下文和用户输入,提示注入可能导致模型执行不当操作,如泄露商业或个人信息。防御措施包括避免在提示中包含敏感信息、使用对抗性提示检测器和微调模型以增强安全性。尽管厂商在改进防御机制,但完全防止攻击仍然困难。
本文探讨了深度强化学习中的对抗攻击,比较了对抗样本与随机噪声攻击的有效性,并提出了一种新方法以降低攻击成功率。研究了随机噪声和FGSM扰动对攻击韧性的影响,提出“对抗风险”作为模型鲁棒性的目标,并发展了新的防御方法,如分层随机切换(HRS)和轻量级防御方法(RND),以提高对抗性和减少性能损失。
本研究提出了一种名为BlueSuffix的新防御方法,旨在增强视觉语言模型(VLMs)抵御监狱逃脱攻击的能力。该方法结合视觉和文本净化器及强化学习微调,显著提升了模型的防御表现,同时保持了良性输入的性能。研究结果表明,BlueSuffix在多项基准测试中优于传统防御方法。
本文研究了大型语言模型(LLMs)面临的越狱攻击及其安全性,提出了多种攻击和防御方法,如PAIR算法、ReNeLLM框架和前缀引导(PG)防御框架。研究表明,现有防御方法存在不足,新技术能够显著提高攻击成功率和模型安全性,为未来研究奠定基础。
本研究探讨了大型语言模型(LLMs)在注入攻击下的脆弱性,并提出了多种防御方法。通过构建包含126,000个攻击示例的数据集,评估了不同模型的鲁棒性。提出的ReNeLLM框架和SelfDefend机制有效降低了攻击成功率。此外,引入的Jatmo模型在特定任务上与标准LLMs的输出质量相当。研究旨在增强LLMs的安全性,推动未来研究。
深度学习中的对抗攻击与防御是一个活跃的研究领域。本文分类了防御方法,并探讨了提高对抗鲁棒性的策略,包括增强特征向量的类内紧凑性和类间分隔性。提出了多类别增强框架和对抗训练方法,以提升模型的鲁棒性,并解决鲁棒性与准确性之间的权衡问题。研究表明,新方法在多个数据集上实现了显著提升。
研究提出了一种生成信号对抗样本的模型,解决深度学习在信号检测任务中的脆弱性。通过L2范数分析,发现当扰动能量比率小于3%时,信号检测网络的精度和召回率显著下降。研究还探讨了多种对抗攻击和防御方法,如AdvGAN、对抗训练和频率分析,提升了检测和防御效果。
完成下面两步后,将自动完成登录并继续当前操作。