


在数百万个集群中运行Kubernetes教会了AWS关于区域故障的知识
The New Stack
·

像部署一样开发:缩小Kubernetes本地与集群之间的差距
The New Stack
·

技嘉科技发布AI TOP ATOM四机串联集群架构
全球TMT-美通国际
·

肖恩·托马斯:期待Postgres 19:面向所有用户的数据校验和
Planet PostgreSQL
·


使用Kubernetes、Argo CD和GitOps构建集群感知的AI代理
Cloud Native Computing Foundation
·
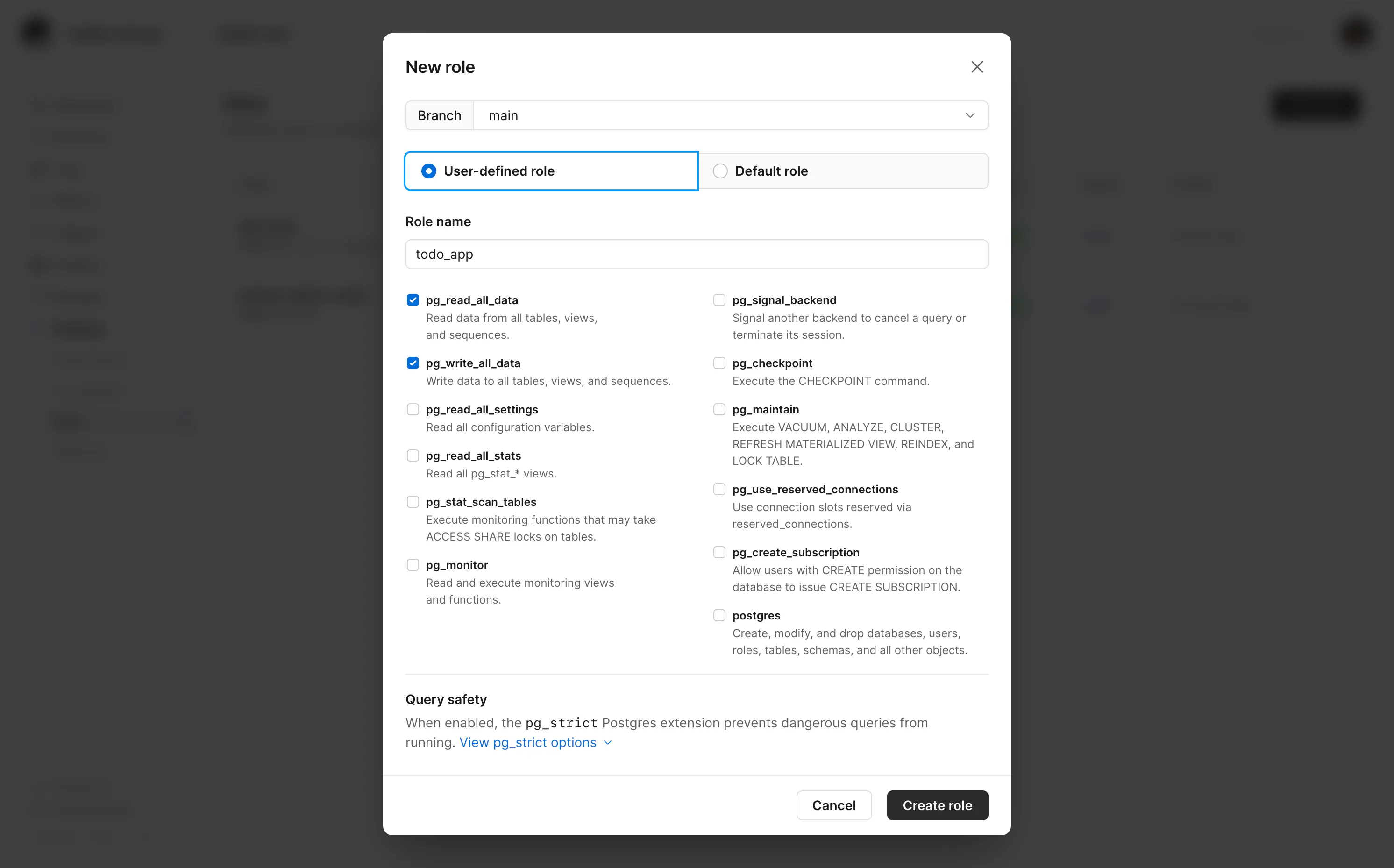
一个Postgres集群,多种应用
PlanetScale - Blog
·


如何构建小型语言模型集群的生产架构
freeCodeCamp.org
·

组复制与Percona XtraDB集群:一致性的真实成本
Percona Database Performance Blog
·

Floor Drees:如何在Kubernetes集群中测试PostgreSQL 19 Beta
Planet PostgreSQL
·

从Crunchy Data PostgreSQL操作员迁移到Percona PostgreSQL操作员:备用集群方法
Percona Database Performance Blog
·
