本文提出了一种名为语言效能刺激(VES)的方法,通过鼓励性、挑衅性和批判性的语言提示,提升大型语言模型在零样本任务中的自我效能和表现。实验结果表明,这三种刺激方式能有效提高模型表现,不同模型对刺激的反应也存在差异,为后续研究提供了新视角。
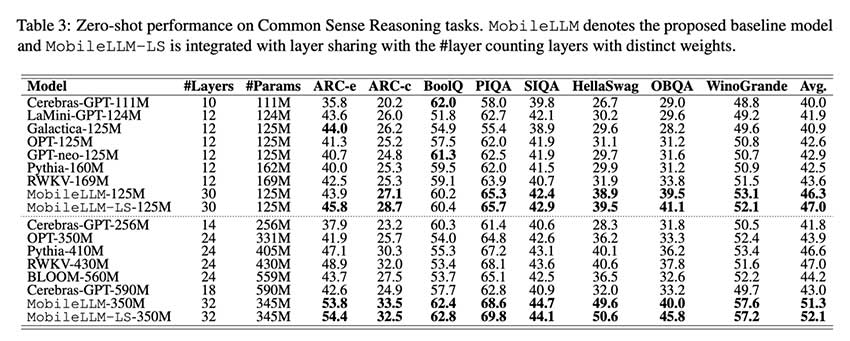
Meta 发布的 MobileLLM 是一组高效的小型语言模型,旨在优化移动设备的部署,减少对云资源的依赖。通过深而薄的架构和多项创新技术,MobileLLM 提供了竞争力的性能,降低了延迟和能耗。在零样本任务中表现优于同类模型,展现了在聊天和 API 调用等应用中的潜力。
7年前,谷歌提出Transformer,随后推出Universal Transformer(UT),通过层共享提升逻辑推理和语言建模性能。近期,研究者提出了Mixture-of-Experts Universal Transformers(MoEUT),结合混合专家架构,提高计算效率和泛化能力。MoEUT在多个数据集上表现优异,特别是在零样本任务中超越标准Transformer。研究显示,MoEUT能动态调整专家选择,适应不同任务需求。
本文探讨了视觉语言模型(VLMs)的性能提升,提出了多种方法改善图像与文本的对齐能力。通过创建ARO基准和CompPrompts数据集,研究了模型对语言信息的编码及其对组合推理的影响。实验表明,优化数据集质量和文本密度显著提高模型性能。此外,提出的加权视觉-文本交叉对齐方法在零样本任务中表现优异,效果与少样本学习相当。
本文介绍了多种基于CLIP模型的开放词汇语义分割方法,如VT-CLIP、CLIP-VIS和NACLIP。这些方法通过引入新模块和技术,显著提升了视频实例分割和语义分割的性能,尤其在零样本任务中表现突出,有效解决了领域偏差和特征对齐问题。
本文提出了一种名为LSTPrompt的新方法,利用大型语言模型(LLMs)进行时间序列预测(TSF),在零样本任务中表现优异。研究总结了基于LLM的时间序列分析流程,探讨了未来研究机会,并提出了TEST方法,通过对时间序列进行编码和提示,提升LLMs的处理能力。实验证明,LLMs在时间序列分类和预测任务中表现出色,尤其在处理具有明确模式的数据时。
本文评估了多模态大型语言模型的指导能力,并引入了I4基准测试。通过重新注入模块和无标注跨注意力引导的训练策略,实现了在复杂的视觉语言指令中有效处理的新型多模态大型语言模型Cheetah。该模型在I4中的零样本任务上表现出色,并与当前MME基准的最新指导优化模型相比具有竞争力的性能。
完成下面两步后,将自动完成登录并继续当前操作。