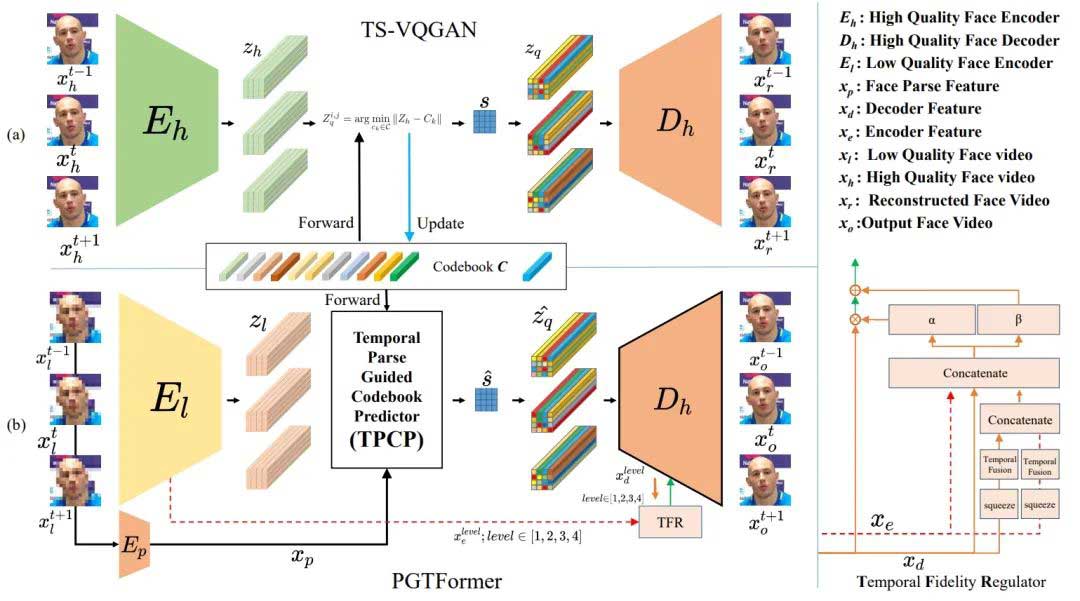
该论文提出了一种名为PGTFormer的盲视频人脸修复模型,通过语义解析的引导选择最佳的面部先验,生成时序一致且无伪影的结果。该模型无需面部预对齐,能提高视频的时序一致性。在多个定量指标和主观视觉对比实验中,该方法表现优异。
完成下面两步后,将自动完成登录并继续当前操作。