
视频人脸修复方案 :无需预对齐的解析引导时序一致性模型 PGTFormer
内容提要
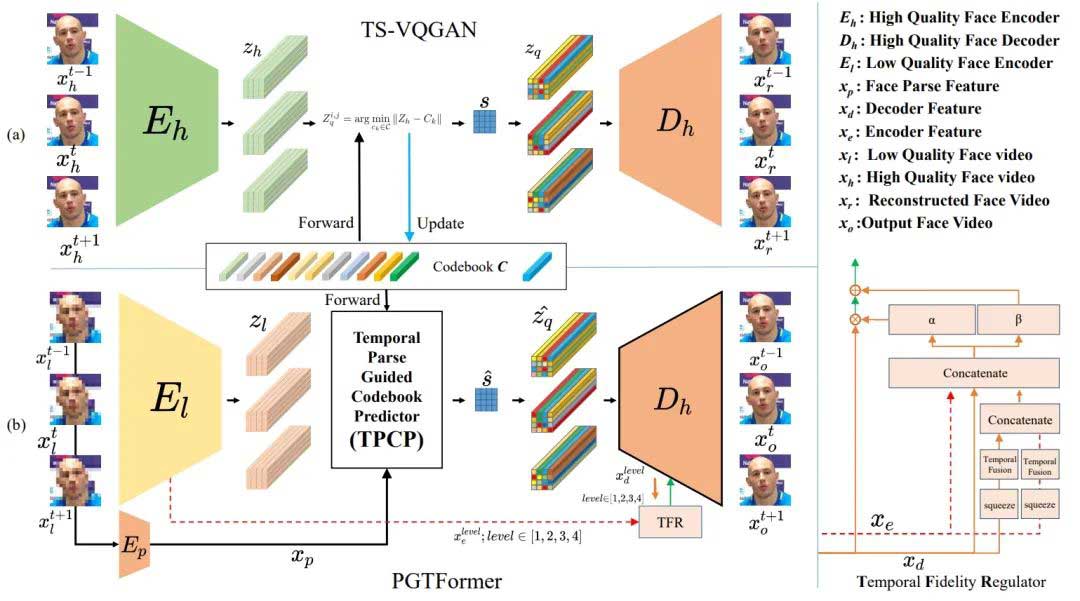
该论文提出了一种名为PGTFormer的盲视频人脸修复模型,通过语义解析的引导选择最佳的面部先验,生成时序一致且无伪影的结果。该模型无需面部预对齐,能提高视频的时序一致性。在多个定量指标和主观视觉对比实验中,该方法表现优异。
关键要点
-
提出了一种名为PGTFormer的盲视频人脸修复模型,无需面部预对齐。
-
PGTFormer通过语义解析引导选择最佳面部先验,生成时序一致且无伪影的结果。
-
模型包括两个关键阶段:TS-VQGAN训练和PGTFormer训练。
-
TS-VQGAN用于捕捉高质量视频人脸的时空特征,提供丰富的先验知识。
-
PGTFormer通过人脸解析模块和时空Transformer模块完成视频人脸修复。
-
PGTFormer设计旨在解决时序一致性不足和复杂对齐操作的问题。
-
通过去除对齐操作,PGTFormer实现了更高效的修复流程。
-
PGTFormer在多个定量指标上表现优异,超越现有修复方法。
-
主观视觉对比实验显示PGTFormer在细节保留和自然度上表现突出。
-
PGTFormer为视频人脸修复领域带来了显著进展,未来将继续优化和扩展应用。
延伸问答
PGTFormer模型的主要创新点是什么?
PGTFormer模型的主要创新点在于无需面部预对齐,通过解析引导选择最佳面部先验,显著提升视频人脸修复的时序一致性和效率。
PGTFormer是如何提高视频人脸修复的时序一致性的?
PGTFormer通过时序保真度调节器增强时序特征的交互,从而提高视频的整体一致性和自然感。
PGTFormer与传统视频人脸修复方法相比有什么优势?
PGTFormer相比传统方法,去除了复杂的对齐操作,采用端到端设计,提升了修复的连贯性和效率。
PGTFormer在定量指标上表现如何?
PGTFormer在PSNR和SSIM等多个定量指标上表现优异,超越了现有的修复方法,证明了其在高质量图像重建方面的能力。
PGTFormer的训练过程分为几个阶段?
PGTFormer的训练过程分为两个阶段:第一阶段是TS-VQGAN训练,第二阶段是PGTFormer训练。
PGTFormer在主观视觉对比实验中表现如何?
在主观视觉对比实验中,PGTFormer在细节保留和自然度上表现突出,尤其在面部关键部位的纹理还原上更为清晰自然。
