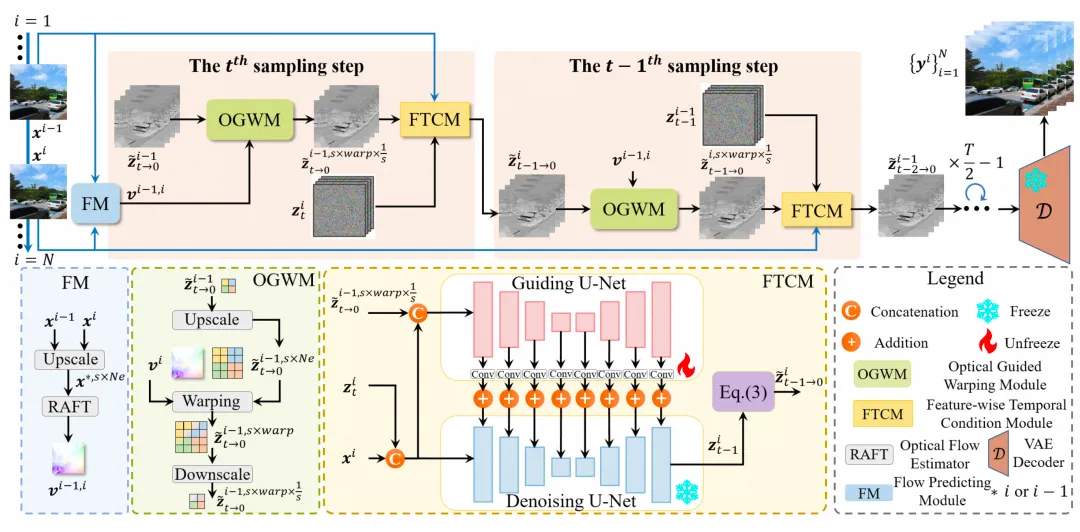
本文介绍了DGAF-VSR,一种基于扩散模型的视频超分辨率方法。该方法通过光流引导变形模块和特征级时序条件模块,显著提升了视频的感知质量、重建保真度和时序一致性。实验结果表明,DGAF-VSR在多个数据集上表现优异,为短视频和直播等应用提供了重要突破。
美团LongCat团队推出的LongCat-Video视频生成模型,通过多任务统一架构,实现高质量长视频生成,具备良好的时序一致性和物理合理性,为自动驾驶等应用奠定基础。
南洋理工大学与商汤科技联合研发的MatAnyone视频抠图技术,能够在复杂背景下高效提取目标。用户只需在首帧指定目标,后续帧将自动稳定抠图,具备良好的细节还原和时序一致性,适用于多种视频处理场景。
本研究提出了RelightVid框架,旨在解决视频重光照中配对数据集不足和高保真度输出的需求。该框架灵活适应多种重光照条件,实现高时序一致性的重光照效果。
可灵(KLING)是快手AI团队推出的全球首个可公开体验的真实影像级视频生成大模型,经过多次功能升级,推动行业发展。其开源数据集Koala-36M提升了视频生成质量,并与清华大学合作提出新的视频生成范式Owl-1,展现了更高的时序一致性和逻辑合理性。
本研究提出了一种基于掩膜的运动轨迹框架,能够将静态图像转化为真实视频序列,有效解决了对象运动不准确和不一致的问题。该方法在多对象和高运动场景中展现了优异的时序一致性和文本提示忠实度。
本研究提出了一种新颖的全端到端口型同步框架LatentSync,基于音频条件的潜在扩散模型,旨在提高时序一致性和口型同步的准确性。
本文提出了StereoCrafter-Zero框架,通过噪声重启和迭代优化,显著改善了立体视频生成中的深度感知和时序一致性问题。
本研究提出了一种新方法RL-V2V-GAN,旨在解决视频到视频合成中的有限标记数据问题。该方法通过增强学习实现源视频到目标视频的映射,同时保持源视频的风格。实验结果表明,在少样本学习条件下,该方法能够生成时序一致的视频。
本研究提出了多种视频生成模型,优化了时序一致性和长视频生成能力。新方法如Gen-L-Video和LaVie,利用文本驱动生成高质量长视频,表现优异。同时介绍了OpenVid-1M数据集和Loong模型,解决了生成长视频的挑战,展现出显著的创新性和实用潜力。
本研究提出了多种视频生成模型,优化了时序一致性和音频驱动效果。通过新方法如EMO和Loopy,提升了说话和肖像视频的真实感与表现力,解决了传统技术的局限性,并展示了高效的动态视频风格化和编辑能力,推动了视频生成技术的发展。
本研究提出了一种名为视频指南的新框架,旨在解决文本到视频生成中的时序一致性问题。该方法利用预训练的视频扩散模型作为引导,显著提高了视频生成的时序质量和图像保真度,具有良好的成本效益和应用潜力。
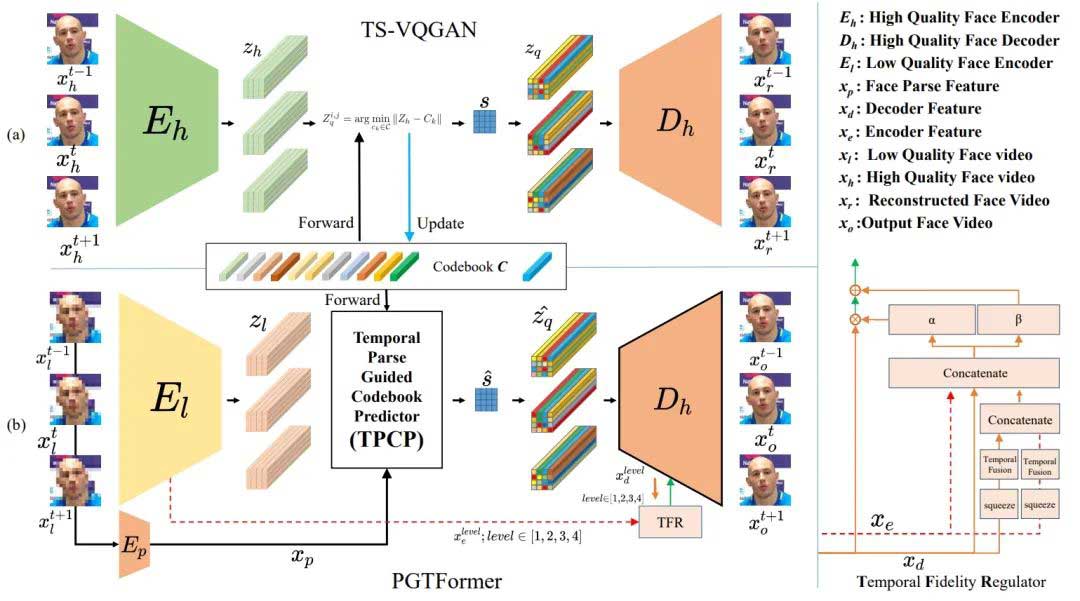
该论文提出了一种名为PGTFormer的盲视频人脸修复模型,通过语义解析的引导选择最佳的面部先验,生成时序一致且无伪影的结果。该模型无需面部预对齐,能提高视频的时序一致性。在多个定量指标和主观视觉对比实验中,该方法表现优异。
本研究提出了多种视频生成模型,如VideoFactory、MovieFactory和VideoDirectorGPT,旨在优化时序一致性和生成质量。通过利用大语言模型和新框架,这些模型能够生成高质量视频,强调视觉一致性和用户偏好。此外,研究探讨了生成AI在视频技术中的应用潜力,并提出了基准测试集TC-Bench,以评估视频生成模型的改进空间。
本研究提出了一种名为VidEdit的零镜头文本视频编辑方法,解决了文本引导视频编辑中的时间不连贯问题,显著提高了视频的时序一致性和编辑能力。该方法在DAVIS数据集上表现优于现有技术,处理速度约为每分钟一段视频。此外,研究还介绍了TI2V-Zero和GenVideo等新方法,进一步提升了视频生成和编辑效果。
本文介绍了一种名为Gen-L-Video的新方法,利用短视频扩散模型生成多样化的长视频,提升视频生成和编辑能力。该方法在多个数据集上验证,性能优于现有技术,用户偏好超过80%。研究还探讨了视频生成模型的时序一致性和高质量生成策略。
本文介绍了一种高效的零样本视频编辑方法EVE,利用深度图和时序一致性约束,快速生成满意的视频编辑结果。同时,提出了Video Instruction Diffusion(VIDiff)模型,支持多种视频任务,并通过迭代自回归方法确保长视频的一致性编辑。研究强调了基于扩散模型的多种视频编辑技术的重要性,特别是时间一致性和高质量生成。
我们提出了一种新颖的零样条移动物体轨迹控制框架Motion-Zero,通过提供基于位置的先验来改善移动物体的外观稳定性和位置准确性,并利用U-net的注意力图在扩散模型的去噪过程中直接应用空间约束,从而进一步确保移动物体的位置和空间一致性,并通过引入移动注意力机制实现时序一致性的保证。这种方法可以灵活运用于各种最先进的视频扩散模型,无需任何训练过程,大量实验证明我们的方法可以控制物体的运动轨迹并生成高质量的视频。
本文介绍了一种基于多视图校准的多人3D姿势估计和跟踪方法,利用时序一致性来匹配先前构建的每个视图中的用2D姿势估计生成的3D骨架,并提出两种策略以实现更好的对应关系和3D重构。该方法在两个基准上取得了竞争性成果,并在Campus测试中取得了良好的结果。
本文提出了一个新的用于验证视频脸部年龄回溯效果的基线架构,并开发了三个新度量指标。实验证明,该方法在年龄转换和时序一致性方面优于现有方法。
完成下面两步后,将自动完成登录并继续当前操作。