JiBA是一款软件,能够自动修复Apple Music中日语歌曲的罗马音和中韩歌曲的翻译名,恢复为原始文字,并支持通过iCloud同步到其他设备。
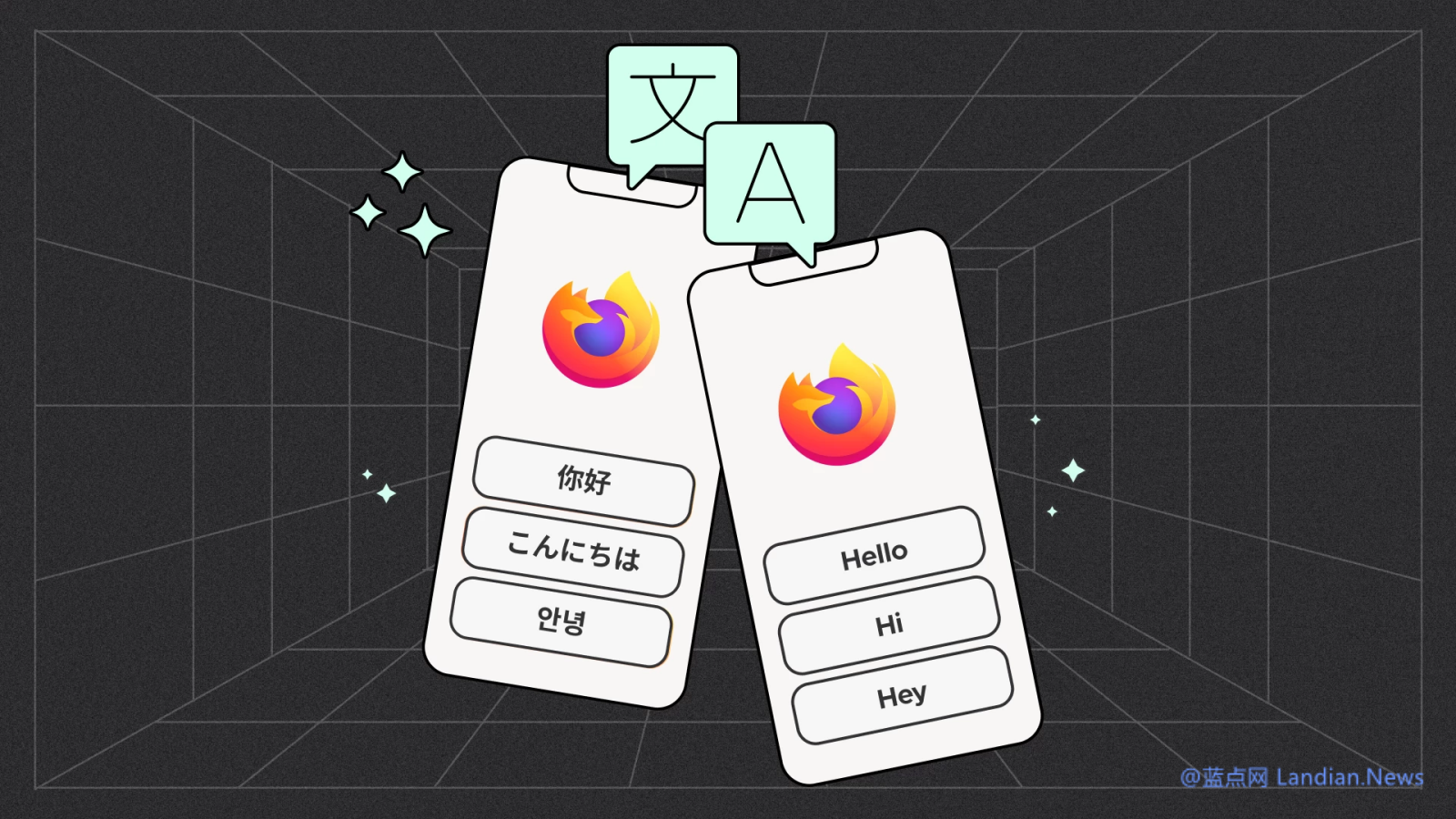
火狐浏览器新增本地翻译功能,支持中文、日文和韩文,保护用户隐私,数据不发送至服务器。用户需更新至最新版本并下载翻译模型后即可使用。该功能已在桌面版和安卓版上线,成功解决了技术挑战。
在Windows上使用国土交通部的公共数据时,文件会出现韩文乱码。用Excel打开可正常显示,但在VSCode或Python中会乱码。解决方法是用Python读取文件并以UTF-8编码写入新文件,然后跳过前15行读取CSV数据。
文章介绍了一系列结合传统与现代设计的韩文字体,适用于品牌、标志、海报和包装等创意项目。这些字体风格多样,展现了韩国文化的独特魅力,支持多语言和多种格式。部分字体可免费用于个人项目,如餐饮包装和社交媒体设计。
cjk-romanizer是一款命令行工具,可将中日韩文命名的文件转换为英文字母。该工具支持多种字符种类和平台,使用简单方便。
《敏捷开发的艺术》韩文版已发布,感谢김모세的翻译工作。该书可在指定网站购买。
该文介绍了一种考虑词素的子词切分方法,用于解决韩语中字节对编码(BPE)的挑战。该方法在预训练语言模型中平衡了语言准确性和计算效率,并在评估中表现良好,提高了句法任务的结果。
本文介绍了一种基于情感分析的新数据集,并训练了一个强大的情感分类器用于议会会议。同时,引入了第一个领域特定的LLM用于政治科学应用,并在27个欧洲议会的会议记录中进行了1.72亿专业领域词汇的预训练。实验证明,LLM在议会数据上的额外预训练可以显著提高模型的性能,尤其是在情感检测等具体领域任务上。
本研究介绍了韩文中最大的冒犯性语言语料库K-HATERS,包含192K个新闻评论,可检测不同程度的仇恨表达。研究者采用认知反思测试作为标签质量的代理,解决了人类注释中的潜在噪声和偏差。该研究对仇恨言论检测和自然语言处理资源构建具有重要贡献。
该研究利用韩国SNS平台的大规模数据集,通过多任务学习和基于BERT的语言模型,实现了对用户生成文本的分类,超越了人类水平的准确性。该方法为减轻仇恨言论和偏见提供了实际解决方案,有助于提升在线社区的健康。
完成下面两步后,将自动完成登录并继续当前操作。