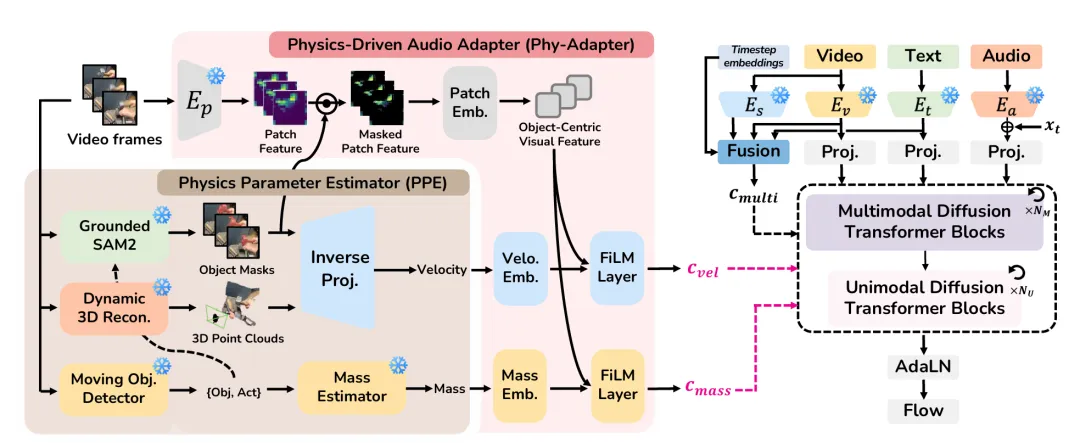
韩国科学技术院等研究团队开发了PAVAS技术,该技术能够根据视频中的物理特性生成更真实的音效。它不仅能识别物体,还能推断物体的质量和速度,从而提升音效与视觉的匹配度。此技术有望在影视、AR/VR等领域应用,推动生成式AI的发展。
本研究提出YingSound模型,解决产品视频生成音效时标记数据不足的问题。该模型通过条件流匹配变换器实现音频与视觉的语义对齐,并引入多模态思维链方法,实验结果表明其能有效生成高质量的同步音效。
AutoFoley 是一种全自动深度学习工具,能够生成与视频同步的逼真音轨。该系统通过提取视频中的关键情节,利用深度学习模型生成音效,简化声音设计过程。研究表明,基于 Transformer 的架构在匹配视觉模式方面表现优秀,Foley Music 系统能生成高质量音乐,优于现有系统。
ElevenLabs推出了一款新的音效生成工具,用户可以通过输入提示生成最多22秒的音效,适用于播客、电影和游戏。该工具与Shutterstock合作,提供音效库。免费用户需在标题中注明“elevenlabs.io”,付费用户可获得商业许可,旨在快速、经济地生成丰富的音效。
完成下面两步后,将自动完成登录并继续当前操作。

/cdn.vox-cdn.com/uploads/chorus_asset/file/25362060/STK_414_AI_CHATBOT_R2_CVirginia_C.jpg)
